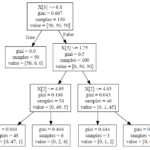
モデルを作成する
プログラム(Python)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# -*- coding: utf-8 -*- import pandas as pd from sklearn import tree import joblib from sklearn.tree import export_text # CSVァイルからデータフレームに読み込む df = pd.read_csv("data_cart.csv") # 説明変数を設定する:x1,x2 x = df.loc[:, ['x1', 'x2']].values # 目的変数を設定する:x3 y = df['x3'].values # モデルを作成する clf = tree.DecisionTreeClassifier() clf.fit(x, y) # ツリーを出力する r = export_text(clf) print(r) # モデルを出力する joblib.dump(clf, 'model_cart.learn') |
データファイル
実行結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|--- feature_0 <= 39.50 | |--- feature_0 <= 34.50 | | |--- class: 30 | |--- feature_0 > 34.50 | | |--- class: 25 |--- feature_0 > 39.50 | |--- feature_0 <= 42.00 | | |--- class: 20 | |--- feature_0 > 42.00 | | |--- feature_0 <= 56.50 | | | |--- feature_1 <= 17.75 | | | | |--- feature_1 <= 16.75 | | | | | |--- class: 35 | | | | |--- feature_1 > 16.75 | | | | | |--- class: 30 | | | |--- feature_1 > 17.75 | | | | |--- feature_1 <= 18.50 | | | | | |--- class: 35 | | | | |--- feature_1 > 18.50 | | | | | |--- feature_0 <= 49.50 | | | | | | |--- class: 35 | | | | | |--- feature_0 > 49.50 | | | | | | |--- class: 40 | | |--- feature_0 > 56.50 | | | |--- class: 45 |
モデルで予測する
入力データファイルは「モデルを作成する」で生成したファイルを使用する。
プログラム(Python)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# -*- coding: utf-8 -*- import pandas as pd import joblib # 学習結果を読み込みする clf = joblib.load('model_cart.learn') # データを読み込みする df = pd.read_csv("data_cart.csv", sep=",") # 説明変数を設定する:x1,x2 x = df.loc[:, ['x1', 'x2']].values # 学習結果を利用して予測する z = clf.predict(x) #予測結果を出力する print(z) |
データファイル
実行結果
|
1 |
[30 25 20 30 45 35 25 35 35 40] |