Pandasを使ってあなたのデータの理解を深める
機械学習プロジェクトの最初のステップは、データに精通することです。 これにはPandasライブラリを使用します。 Pandasは、データサイエンティストがデータの探索と操作に使用する主要なツールです。 ほとんどの人は、コード内でPandasをpdと省略しています。 コマンドでこれを行います

Pandasライブラリの最も重要な部分はDataFrameです。 DataFrameは、テーブルのようなデータタイプを保持します。 これは、Excelのシート、またはSQLデータベースのテーブルに似ています。
Pandasには、このデータタイプで実行したいほとんどのことに対して強力なメソッドがあります。
例として、オーストラリアのメルボルンの住宅価格に関するデータを見てみましょう。 実践的な演習では、アイオワ州の住宅価格を持つ新しいデータセットに同じプロセスを適用します。
サンプル(メルボルン)データは、ファイルパス../input/melbourne-housing-snapshot/melb_data.csvにあります。
次のコマンドを使用して、データをロードして調査します。

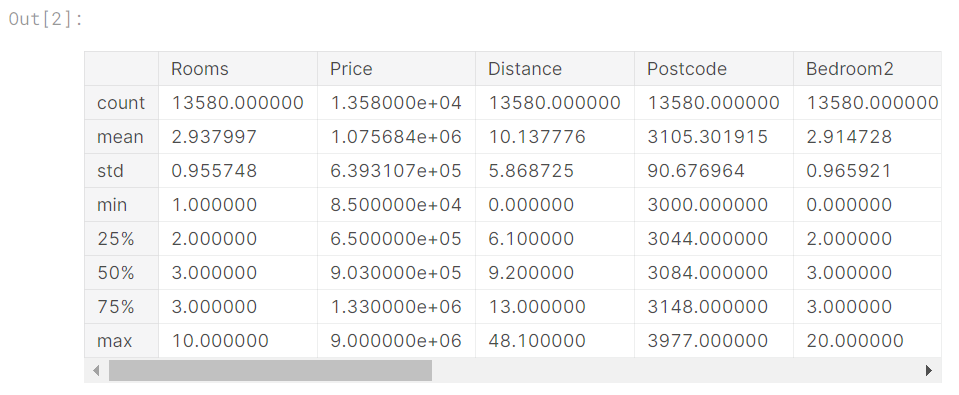
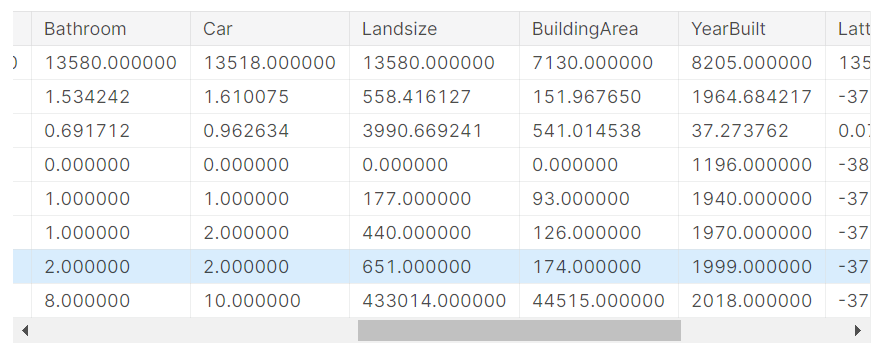
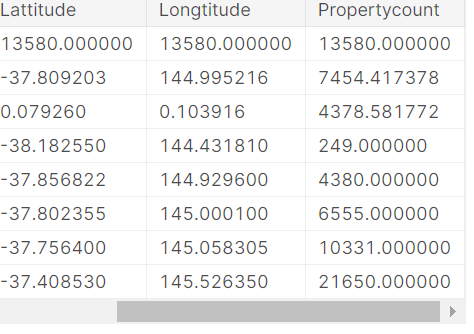
データの説明の解釈
実行結果には、元のデータセットの各列に8つの数値が表示されます。 最初の数値であるcountは、欠落していない値を持つ行の数を示します。
欠測値は多くの理由で発生します。 たとえば、1ベッドルームの家を調査する場合、2ベッドルームのサイズは収集されません。 欠測データのトピックに戻ります。
2番目の値はmeanであり、これは平均です。 その下で、stdは標準偏差であり、値がどの程度数値的に分散しているかを測定します。
min、25%、50%、75%、およびmaxを解釈するために、各列を最小値から最大値に並べ替えることを想像してください。 最初の(min)値は最小値です。 リストを4分の1進むと、値の25%より大きく、75%より小さい数値が見つかります。 これは25%の値です(「25パーセンタイル」と発音します)。 50パーセンタイルと75パーセンタイルも同様に定義され、maxが最大数です。
あなたの番です
最初のコーディング演習を開始します
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
