モデリング用のデータの選択
データセットの変数が多すぎて、頭を包み込んだり、うまく印刷したりすることさえできませんでした。 この圧倒的な量のデータを、理解できるものにどのように削減できますか?
直感を使用していくつかの変数を選択することから始めます。 後のコースでは、変数に自動的に優先順位を付けるための統計手法を紹介します。
変数/列を選択するには、データセット内のすべての列のリストを表示する必要があります。 これは、DataFrameのcolumnsプロパティ(以下のコードの一番下の行)を使用して行われます。
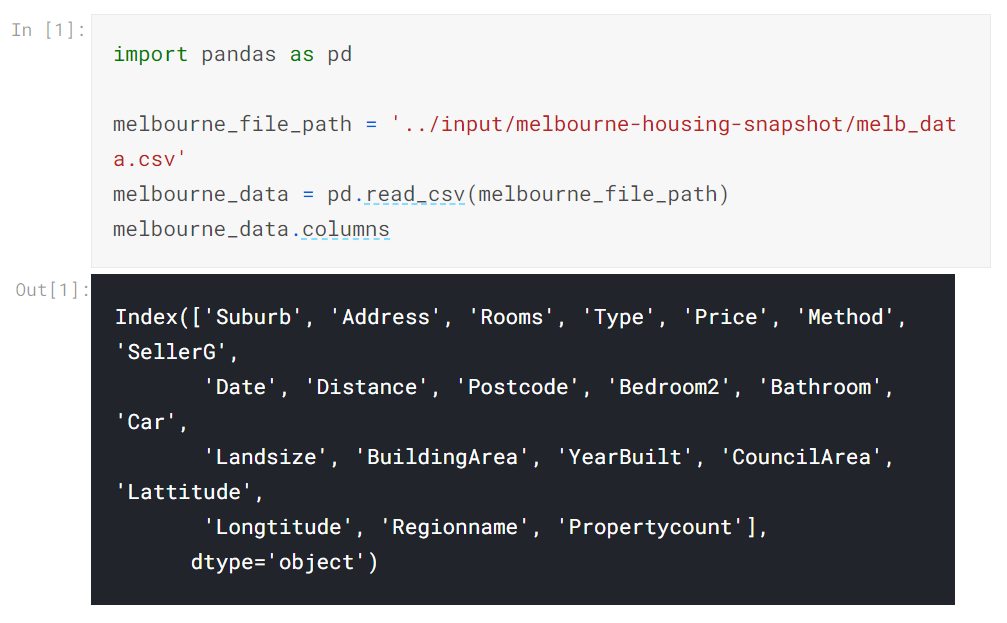

#メルボルンのデータにはいくつかの欠落値があります(いくつかの変数が記録されていないいくつかの家)。
#後のチュートリアルで欠落値の処理方法を学習します。
#アイオワデータでは、使用する列に欠測値がありません。
#それで、今のところ最も単純なオプションを取り、データから家を削除します。
#コードは次のとおりですが、今のところこれについてはそれほど心配しないでください。
#dropnaは欠落している値を削除します(naを「利用不可」と考えてください)
データのサブセットを選択する方法はたくさんあります。 Pandas Micro-Courseはこれらをより深くカバーしていますが、ここでは2つのアプローチに焦点を当てます。
1.「予測対象」の選択に使用するドット表記
2.「機能」の選択に使用する列リストによる選択
予測ターゲットの選択
ドット表記で変数を引き出すことができます。 この単一の列はシリーズに格納されます。これは、データの単一の列のみを持つDataFrameに広く似ています。
ドット表記を使用して、予測対象と呼ばれる予測する列を選択します。 慣例により、予測ターゲットはyと呼ばれます。 したがって、メルボルンのデータに住宅価格を保存するために必要なコードは次のとおりです。

「機能」の選択
モデルに入力された(そして後で予測を行うために使用される)列は、「特徴」と呼ばれます。 私たちの場合、それらは住宅価格を決定するために使用される列になります。 ターゲットを除くすべての列を機能として使用する場合があります。 また、機能が少ない方が良い場合もあります。
今のところ、いくつかの機能のみを備えたモデルを作成します。 後で、さまざまな機能で構築されたモデルを反復して比較する方法を説明します。
括弧内に列名のリストを提供することにより、複数の機能を選択します。 そのリストの各項目は文字列(引用符付き)である必要があります。
次に例を示します。

慣例により、このデータはXと呼ばれます。

上位数行を表示するdescribeメソッドとheadメソッドを使用して住宅価格を予測するために使用するデータを簡単に確認してみましょう。
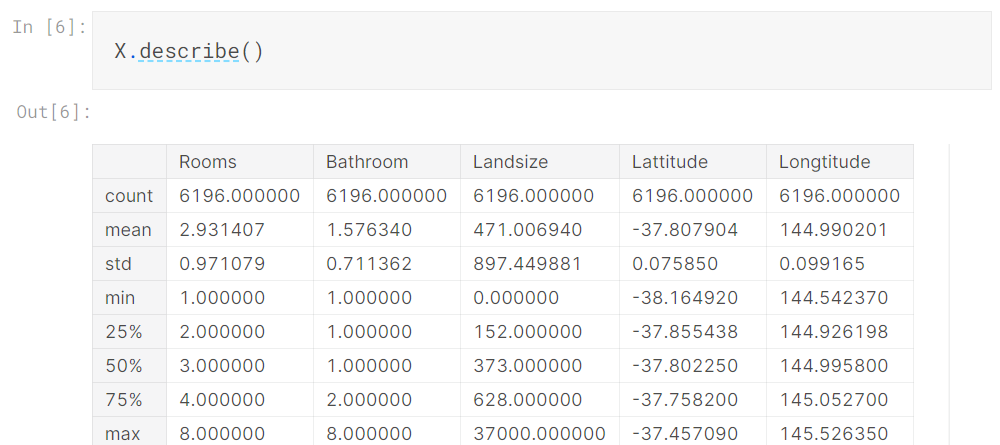
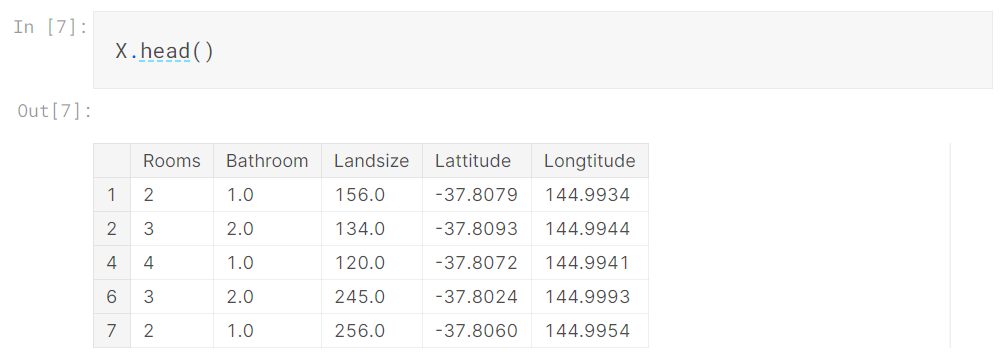
これらのコマンドを使用してデータを視覚的に確認することは、データサイエンティストの仕事の重要な部分です。 データセットには、さらに調査する価値のある驚きが頻繁にあります。
モデルの構築
scikit-learnライブラリを使用してモデルを作成します。 サンプルコードに示されているように、コーディング時には、このライブラリはsklearnとして記述されます。 Scikit-learnは、DataFrameに通常保存されるデータの種類をモデル化するための最も一般的なライブラリです。
モデルを作成して使用する手順は次のとおりです。
・定義:どのようなモデルになりますか? デシジョンツリー? 他のタイプのモデル? モデルタイプの他のいくつかのパラメータも指定されています。
・適合:提供されたデータからパターンをキャプチャします。 これがモデリングの中心です。
・予測:どのように聞こえるか
・評価:モデルの予測がどれだけ正確かを判断します。
これは、scikit-learnを使用してデシジョンツリーモデルを定義し、それを機能とターゲット変数に適合させる例です。
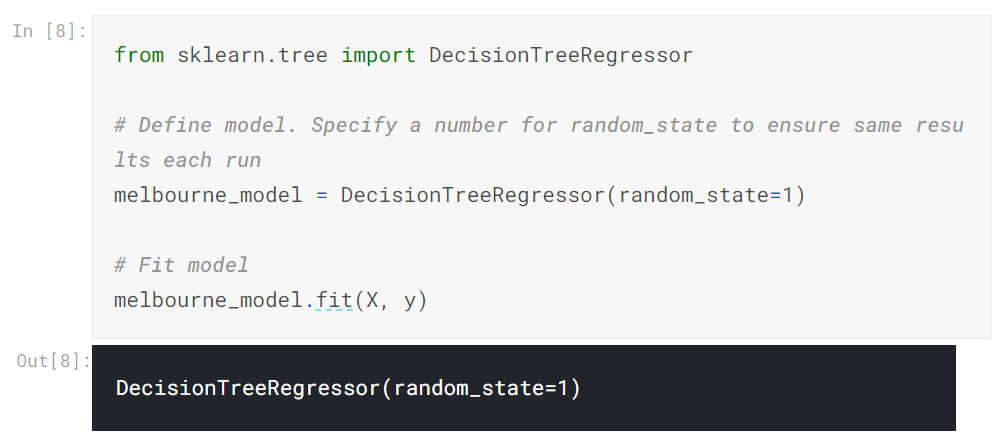
多くの機械学習モデルでは、モデルのトレーニングにある程度のランダム性があります。 random_stateに数値を指定すると、各実行で同じ結果が得られます。 これは良い習慣と考えられています。 任意の数を使用します。モデルの品質は、選択した値に正確に依存することはありません。
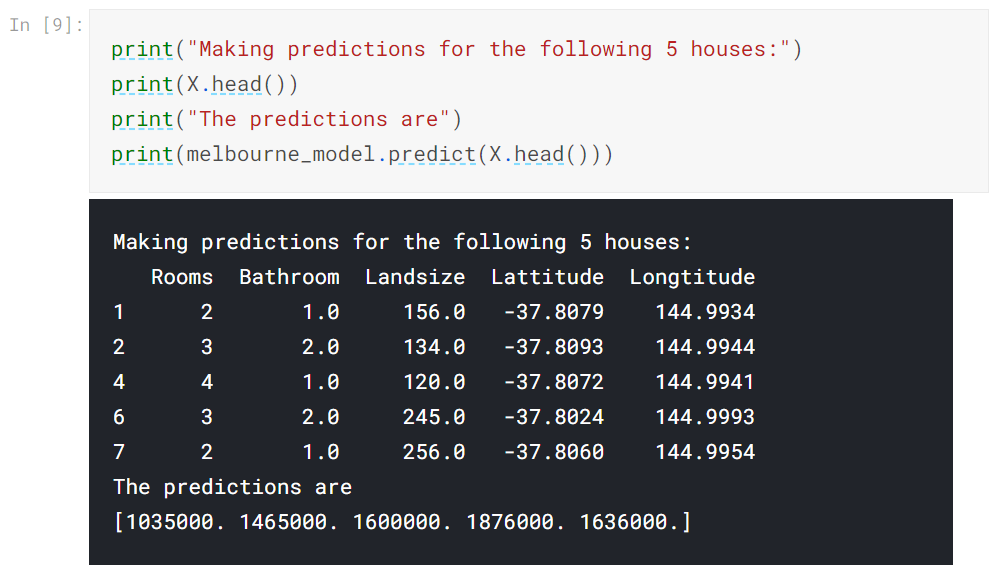
これで、予測に使用できる近似モデルができました。
実際には、すでに価格が設定されている家ではなく、市場に出回る新しい家を予測する必要があります。 ただし、トレーニングデータの最初の数行を予測して、予測関数がどのように機能するかを確認します。
あなたの番です
モデル構築の演習で自分で試してみてください
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
