要約
これまでに、データをロードし、次のコードで確認しました。 このセルを実行して、前の手順で中断したコーディング環境をセットアップします。

実行結果
演習
ステップ1:予測ターゲットを指定する
販売価格に対応するターゲット変数を選択します。 これをyという新しい変数に保存します。 必要な列の名前を見つけるには、列のリストを印刷する必要があります。


実行結果


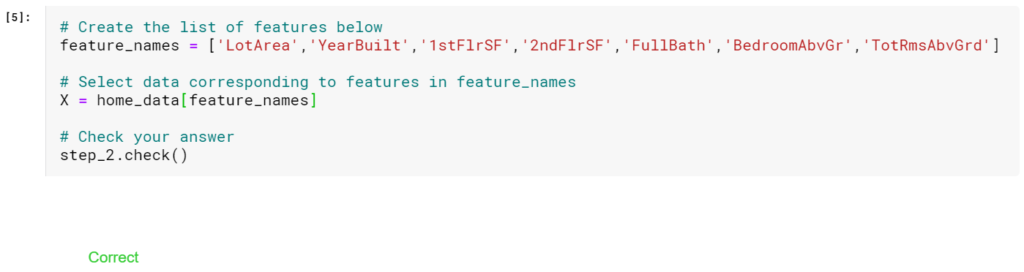
ステップ2:Xを作成する
次に、予測機能を保持するXというDataFrameを作成します。
元のデータの一部の列のみが必要なため、最初にXで必要な列の名前を使用してリストを作成します。
リストでは次の列のみを使用します(リスト全体をコピーして貼り付けると、入力を節約できますが、引用符を追加する必要があります)。

機能のリストを作成したら、それを使用して、モデルの適合に使用するDataFrameを作成します。

実行結果

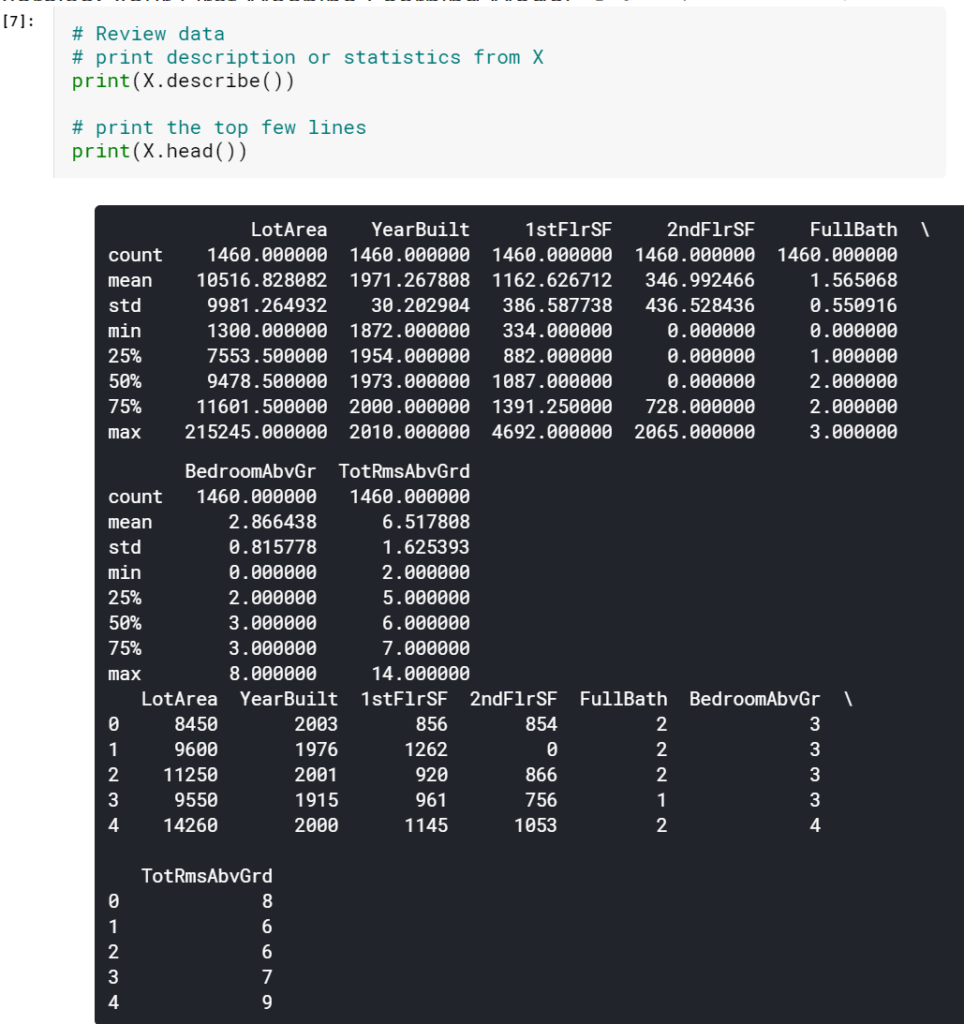
データの確認
モデルを作成する前に、Xをざっと見て、適切に見えることを確認してください

実行結果
ステップ3:モデルを指定して適合させる
DecisionTreeRegressorを作成し、iowa_modelに保存します。 このコマンドを実行するには、sklearnから関連するインポートを実行したことを確認してください。
次に、上で保存したXとyのデータを使用して作成したモデルを適合させます。

実行結果


ステップ4:予測を行う
Xをデータとして使用して、モデルのpredictコマンドで予測を行います。 結果をpredictionsと呼ばれる変数に保存します。

実行結果


結果について考える
headメソッドを使用して、上位のいくつかの予測を、それらの同じ家の実際の家の値(y単位)と比較します。 何か驚くべきことはありますか?

モデルの予測がどれほど正確であり、それをどのように改善できるかを尋ねるのは自然なことです。 それはあなたが次のステップになるでしょう。
次に進もう
モデル検証の準備が整いました。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
