今度は、欠測値の処理に関する新しい知識をテストする番です。 あなたはおそらくそれが大きな違いを生むことに気付くでしょう。
準備
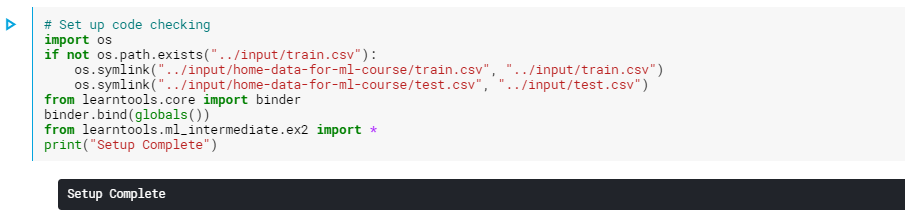
質問はあなたの仕事についてのフィードバックを与えるでしょう。 次のセルを実行して、フィードバックシステムを設定します。

実行結果
この演習では、KaggleLearnユーザー向けの住宅価格コンペティションのデータを使用します。

変更せずに次のコードセルを実行して、X_train、X_valid、y_train、およびy_validのトレーニングセットと検証セットを読み込みます。 テストセットはX_testにロードされます。

次のコードセルを使用して、データの最初の5行を出力します。

実行結果

最初の数行には、すでにいくつかの欠落値があります。 次のステップでは、データセットの欠落値をより包括的に理解します。
ステップ1:予備調査
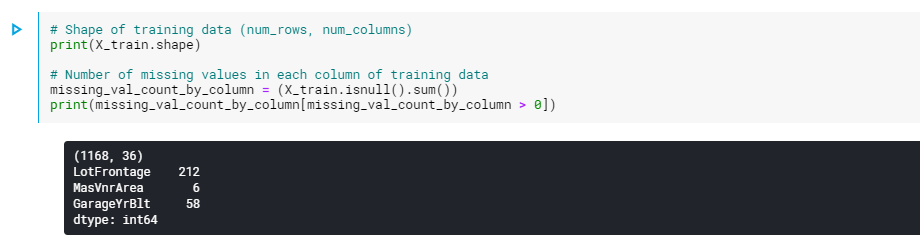
以下のコードセルを変更せずに実行します。

実行結果
パートA
上記の出力を使用して、以下の質問に答えてください。

実行結果


パートB
上記の回答を考慮すると、欠測値に対処するための最善のアプローチは何だと思いますか?

実行結果
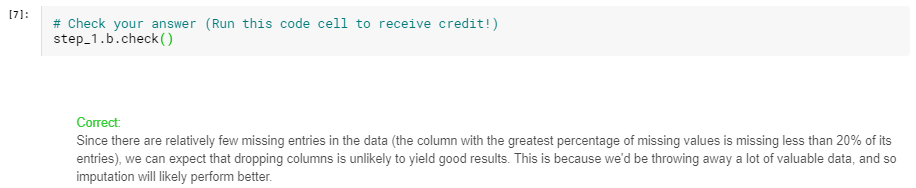
データ内の欠落しているエントリは比較的少ないため(欠落している値の割合が最も高い列は、欠落しているエントリの20%未満です)、列を削除しても良好な結果が得られない可能性があります。 これは、多くの貴重なデータを破棄するため、代入のパフォーマンスが向上する可能性が高いためです。

欠落値を処理するためのさまざまなアプローチを比較するには、チュートリアルと同じscore_dataset()関数を使用します。 この関数は、ランダムフォレストモデルからの平均絶対誤差(MAE)を報告します。

手順2:値が欠落している列を削除する
このステップでは、X_trainおよびX_validのデータを前処理して、値が欠落している列を削除します。 前処理されたDataFrameをそれぞれreduced_X_trainとreduced_X_validに設定します。

実行結果


このアプローチのMAEを取得するには、変更せずに次のコードセルを実行します。

実行結果

ステップ3:代入
パートA
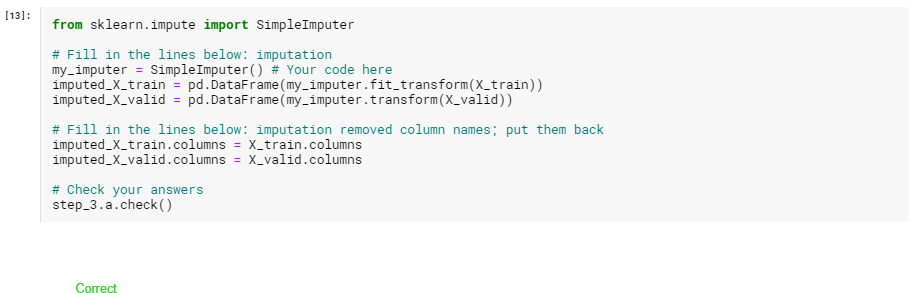
次のコードセルを使用して、各列に沿った平均値で欠落値を代入します。 前処理されたDataFrameをimputed_X_trainおよびimputed_X_validに設定します。 列名がX_trainおよびX_validの列名と一致していることを確認してください。

実行結果

このアプローチのMAEを取得するには、変更せずに次のコードセルを実行します。

実行結果

パートB
各アプローチのMAEを比較します。 結果について何か驚いたことはありますか? なぜ一方のアプローチが他方よりも優れていると思いますか?

実行結果
データセットに欠落している値が非常に少ないことを考えると、列を完全に削除するよりも代入の方がパフォーマンスが高いと予想されます。ただし、列を削除するとパフォーマンスがわずかに向上することがわかります。これはおそらくデータセット内のノイズに部分的に起因している可能性がありますが、別の潜在的な説明は、代入方法がこのデータセットとあまり一致していないことです。つまり、平均値を入力する代わりに、欠落しているすべての値を値0に設定するか、最も頻繁に発生する値を入力するか、または他の方法を使用する方が理にかなっています。たとえば、GarageYrBlt列(ガレージが建設された年を示します)について考えてみます。場合によっては、値が欠落している場合は、ガレージがない家を示している可能性があります。この場合、各列に沿って中央値を入力する方が理にかなっていますか?または、各列に沿って最小値を入力することで、より良い結果を得ることができますか?この場合に何が最適かは明確ではありませんが、いくつかのオプションをすぐに除外できる可能性があります。たとえば、この列の欠落値を0に設定すると、恐ろしい結果が生じる可能性があります。

ステップ4:テスト予測を生成する
この最後のステップでは、選択した任意のアプローチを使用して、欠落している値を処理します。 トレーニング機能と検証機能を前処理したら、ランダムフォレストモデルをトレーニングして評価します。 次に、コンテストに提出できる予測を生成する前に、テストデータを前処理します。
パートA
次のコードセルを使用して、トレーニングデータと検証データを前処理します。 前処理されたDataFrameをfinal_X_trainおよびfinal_X_validに設定します。 ここでは、任意のアプローチを使用できます。 このステップが正しいとマークされるためには、以下を確認するだけで済みます。
- 前処理されたDataFrameには、同じ数の列があります。
- 前処理されたDataFrameには欠測値がありません。
- final_X_trainとy_trainの行数は同じで、
- final_X_validとy_validの行数は同じです。

実行結果


次のコードセルを実行して、ランダムフォレストモデルをトレーニングおよび評価します。 (トレーニング済みモデルを使用してテスト予測を生成するため、上記のscore_dataset()関数は使用しないことに注意してください!)

実行結果

パートB
次のコードセルを使用して、テストデータを前処理します。 トレーニングデータと検証データを前処理した方法と一致する方法を使用し、前処理されたテスト機能をfinal_X_testに設定していることを確認してください。
次に、前処理されたテスト機能とトレーニングされたモデルを使用して、preds_testでテスト予測を生成します。
このステップが正しいとマークされるためには、以下を確認するだけで済みます。
- 前処理されたテストDataFrameには欠測値がない
- final_X_testには、X_testと同じ行数がある

実行結果


変更せずに次のコードセルを実行して、結果をCSVファイルに保存します。CSVファイルは、コンテストに直接送信できます。

結果を送信する
ステップ4を正常に完了すると、結果をリーダーボードに送信する準備が整います。 (前の演習でこれを行う方法も学びました。これを行う方法のリマインダーが必要な場合は、以下の手順を使用してください。)
まず、まだ参加していない場合は、コンテストに参加する必要があります。 したがって、このリンクをクリックして新しいウィンドウを開きます。 次に、[コンテストに参加]ボタンをクリックします。

次に、以下の手順に従ってください。
- ウィンドウの右上隅にある青い[Save Version]ボタンをクリックすることから始めます。 これにより、ポップアップウィンドウが生成されます。
- [Save & Run All(Commit)]オプションが選択されていることを確認してから、青い[Save]ボタンをクリックします。
- これにより、ノートブックの左下隅にウィンドウが生成されます。 実行が終了したら、[Save Version]ボタンの右側にある番号をクリックします。 これにより、画面の右側にバージョンのリストが表示されます。 最新バージョンの右側にある省略記号(…)をクリックし、[Open in Viewer]を選択します。 これにより、同じページの表示モードになります。 これらの手順に戻るには、下にスクロールする必要があります。
- 画面右側の[Output]タブをクリックします。 次に、送信するファイルをクリックし、青い[Submit]ボタンをクリックして、結果をリーダーボードに送信します。
これで、コンテストへの応募に成功しました。
パフォーマンスを向上させるために作業を続けたい場合は、画面の右上にある青い[Edit]ボタンを選択します。 次に、コードを変更してプロセスを繰り返すことができます。 改善の余地はたくさんあり、作業しながらリーダーボードに登ります。
次に進もう
カテゴリ変数とは何か、およびそれらを機械学習モデルに組み込む方法について学習します。 カテゴリ変数は実際のデータでは非常に一般的ですが、最初に処理せずにモデルにプラグインしようとするとエラーが発生します。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
