このチュートリアルでは、このタイプのデータを処理するための3つのアプローチとともに、カテゴリ変数とは何かを学習します。
はじめに
カテゴリ変数は、限られた数の値のみを取ります。
- 朝食をとる頻度を尋ね、「まったくない」、「ほとんどない」、「ほとんどの日」、「毎日」の4つの選択肢がある調査を検討してください。 この場合、応答は固定されたカテゴリのセットに分類されるため、データはカテゴリに分類されます。
- 所有している車のブランドを調査したところ、「ホンダ」「トヨタ」「フォード」などに分類されます。 この場合、データもカテゴリに分類されます。
これらの変数を最初に前処理せずにPythonのほとんどの機械学習モデルにプラグインしようとすると、エラーが発生します。 このチュートリアルでは、カテゴリデータの準備に使用できる3つのアプローチを比較します。
3つのアプローチ
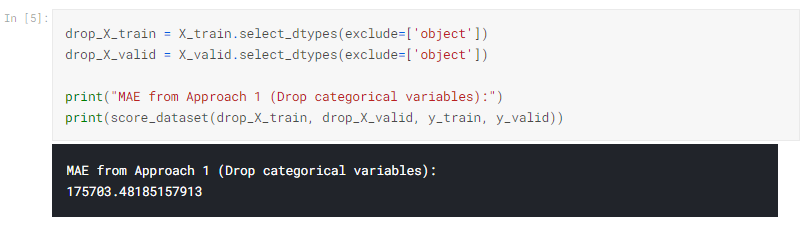
1)カテゴリ変数を削除する
カテゴリ変数を処理する最も簡単な方法は、データセットから変数を削除することです。 このアプローチは、列に有用な情報が含まれていない場合にのみうまく機能します。
2)ラベルエンコーディング
ラベルエンコーディングは、それぞれの一意の値を異なる整数に割り当てます。
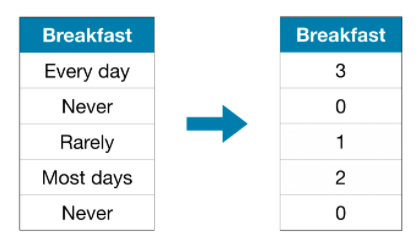
このアプローチでは、カテゴリの順序を「まったくない」(0)<「ほとんどない」(1)<「ほとんどの日」(2)<「毎日」(3)と想定しています。 この例では、カテゴリに議論の余地のないランキングがあるため、この仮定は理にかなっています。 すべてのカテゴリ変数の値に明確な順序があるわけではありませんが、順序変数と呼びます。 ツリーベースのモデル(決定木やランダムフォレストなど)の場合、ラベルエンコーディングが順序変数でうまく機能することが期待できます。
3)ワンホットエンコーディング
ワンホットエンコーディングは、元のデータに可能な各値の存在(または不在)を示す新しい列を作成します。 これを理解するために、例を見ていきます。
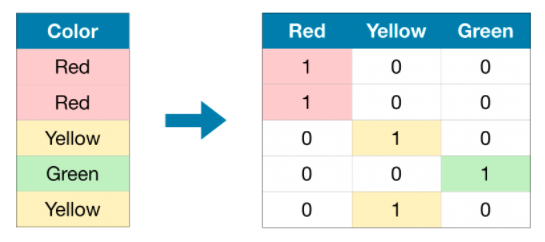
元のデータセットでは、「Color」は「Red」、「Yellow」、「Green」の3つのカテゴリを持つカテゴリ変数です。 対応するワンホットエンコーディングには、可能な値ごとに1つの列が含まれ、元のデータセットの各行に1つの行が含まれます。 元の値が「赤」の場合は常に、「赤」列に1を入力します。 元の値が「Yellow」の場合、「Yellow」列に1を入力します。
ラベルエンコーディングとは対照的に、ワンホットエンコーディングはカテゴリの順序を想定していません。 したがって、カテゴリデータに明確な順序がない場合(たとえば、「赤」が「黄色」以上でも以下でもない場合)、このアプローチが特にうまく機能することが期待できます。 固有のランク付けのないカテゴリ変数を名義変数と呼びます。
ワンホットエンコーディングは、一般に、カテゴリ変数が多数の値をとる場合はうまく機能しません(つまり、通常、15を超える異なる値をとる変数には使用しません)。
例えば
前のチュートリアルと同様に、MelbourneHousingデータセットを使用します。
データの読み込み手順には焦点を当てません。 代わりに、X_train、X_valid、y_train、およびy_validにトレーニングおよび検証データがすでにある時点にいると想像できます。
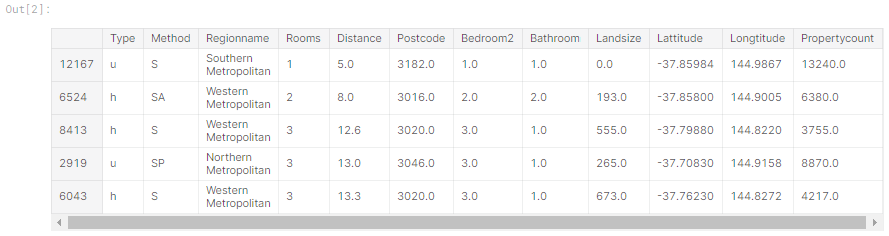
以下のhead()メソッドを使用してトレーニングデータを確認します。

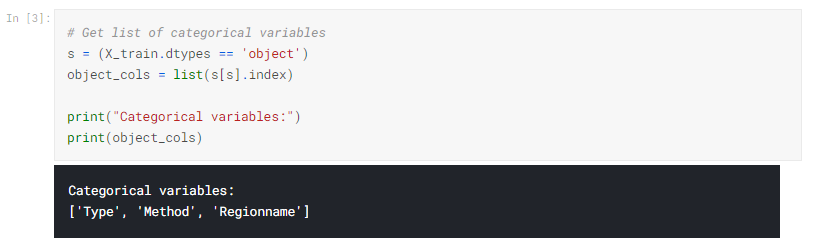
次に、トレーニングデータ内のすべてのカテゴリ変数のリストを取得します。
これを行うには、各列のデータ型(またはdtype)を確認します。 オブジェクトdtypeは、列にテキストがあることを示します(理論的には他にもありますが、それは私たちの目的にとって重要ではありません)。 このデータセットの場合、テキストのある列はカテゴリ変数を示します。
各アプローチの品質を測定する関数を定義する
関数score_dataset()を定義して、カテゴリ変数を処理するための3つの異なるアプローチを比較します。 この関数は、ランダムフォレストモデルからの平均絶対誤差(MAE)を報告します。 一般的に、MAEはできるだけ低くする必要があります。
アプローチ1のスコア(カテゴリ変数の削除)
select_dtypes()メソッドを使用してオブジェクト列を削除します。
アプローチ2(ラベルエンコーディング)からのスコア
Scikit-learnには、ラベルエンコーディングを取得するために使用できるLabelEncoderクラスがあります。 カテゴリ変数をループし、ラベルエンコーダーを各列に個別に適用します。
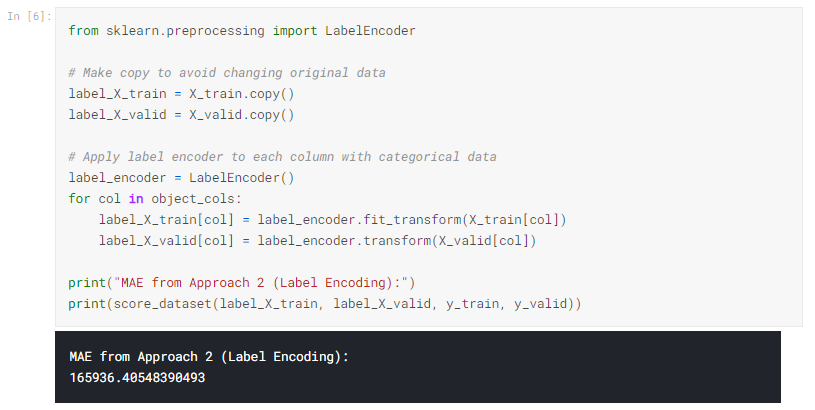
上記のコードセルでは、列ごとに、一意の値をそれぞれ異なる整数にランダムに割り当てます。 これは、カスタムラベルを提供するよりも簡単な一般的なアプローチです。 ただし、すべての順序変数に十分な情報に基づいたラベルを提供すると、パフォーマンスがさらに向上することが期待できます。
アプローチ3(ワンホットエンコーディング)のスコア
scikit-learnのOneHotEncoderクラスを使用して、ワンホットエンコーディングを取得します。 その動作をカスタマイズするために使用できるパラメータがいくつかあります。
- 検証データにトレーニングデータに表されていないクラスが含まれている場合のエラーを回避するために、handle_unknown = ‘ignore’を設定する
- sparse = Falseを設定すると、エンコードされた列が(スパース行列ではなく)numpy配列として返される。
エンコーダーを使用するために、ワンホットエンコードするカテゴリ列のみを提供します。 たとえば、トレーニングデータをエンコードするために、X_train [object_cols]を提供します。 (以下のコードセルのobject_colsは、カテゴリデータを含む列名のリストであるため、X_train [object_cols]にはトレーニングセット内のすべてのカテゴリデータが含まれています。)
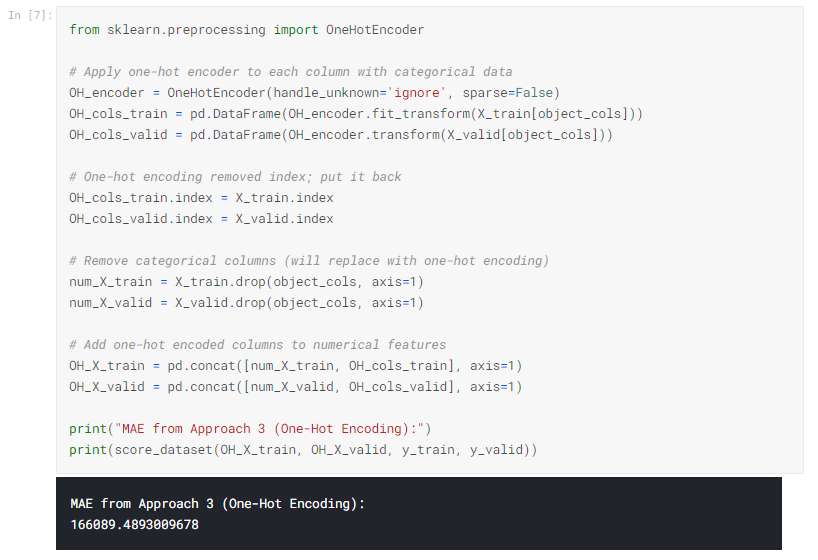
どのアプローチが最適ですか?
この場合、カテゴリ列の削除(アプローチ1)は、MAEスコアが最も高かったため、パフォーマンスが最悪でした。 他の2つのアプローチに関しては、返されるMAEスコアの値が非常に近いため、一方に他方よりも意味のある利点はないようです。
一般に、ワンホットエンコーディング(アプローチ3)は通常最高のパフォーマンスを発揮し、カテゴリ列の削除(アプローチ1)は通常最低のパフォーマンスを発揮しますが、ケースバイケースで異なります。
結論
世界はカテゴリーデータでいっぱいです。 この一般的なデータ型の使用方法を知っていれば、はるかに効果的なデータサイエンティストになります。
あなたの番
次の演習で新しいスキルを活用してください。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
