このチュートリアルでは、モデルのパフォーマンスをより適切に測定するために相互検証を使用する方法を学習します。
はじめに
機械学習は反復的なプロセスです。
使用する予測変数、使用するモデルのタイプ、それらのモデルに提供する引数などの選択に直面します。これまでは、検証(またはホールドアウト)セットを使用してモデルの品質を測定することにより、データ駆動型の方法でこれらの選択を行ってきました。
しかし、このアプローチにはいくつかの欠点があります。これを確認するために、5000行のデータセットがあるとします。通常、データの約20%つまり1000行を検証データセットとして保持します。しかし、これはモデルのスコアを決定する際にランダム性を残します。つまり、モデルは、別の1000行では不正確であっても、1000行の1つのセットでうまく機能する可能性があります。
極端な場合、検証セットに1行のデータしかないことを想像できます。代替モデルを比較する場合、単一のデータポイントでどのモデルが最良の予測を行うかは、ほとんどの場合運の問題です。
一般に、検証セットが大きいほど、モデル品質の測定におけるランダム性(別名「ノイズ」)が少なくなり、信頼性が高くなります。残念ながら、トレーニングデータから行を削除することによってのみ、大きな検証セットを取得できるので、トレーニングデータセットが小さいほど、モデルが悪化します。
相互検証とは何ですか?
相互検証では、データのさまざまなサブセットに対してモデリングプロセスを実行して、モデル品質の複数の測定値を取得します。
たとえば、完全なデータセットを5つの部分に分割して、それぞれが全体の20%になるようにすることから始めることができます。このことを、データを5つの「フォールド」に分割したと言います。
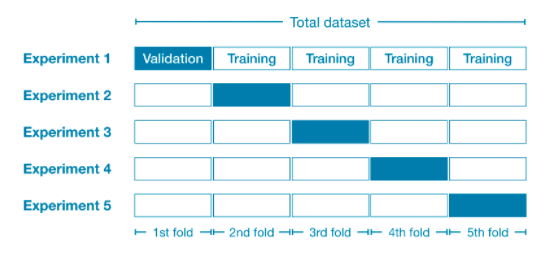
次に、フォールドごとに1つの実験を実行します。
- 実験1では、最初のフォールドを検証(またはホールドアウト)セットとして使用し、その他すべてをトレーニングデータとして使用します。これにより、20%のホールドアウトセットに基づいたモデル品質の測定値が得られます。
- 実験2では、2番目のフォールドを検証(またはホールドアウト)セットとして使用し、2番目のフォールド以外をトレーニングデータとして使用します。これにより、2番目のフォールドを使用して、モデル品質の2番目の推定値を取得します。
- すべてのフォールドを1回ずつホールドアウトセットとして使用して、このプロセスを繰り返すことで、ある時点でデータの100%がホールドアウトとして使用され、データセット内のすべての行に基づくモデル品質の測定値が得られます(すべての行を同時に使用しなくても) 。
いつ相互検証を使用する必要がありますか?
相互検証により、モデルの品質をより正確に測定できます。これは、モデリングに関する多くの決定を行う場合に特に重要です。ただし、複数のフォールドごとに推定するため、実行に時間がかかる場合があります。
つまり、これらのトレードオフを考えると、各アプローチをいつ使用する必要があるか?
- 余分な計算負荷がそれほど大きくない小さなデータセットの場合は、相互検証を実行する必要があります。
- 大規模なデータセットの場合、単一の検証セットで十分です。十分なデータがあるため、ホールドアウトのためにその一部を再利用する必要はほとんどありません。
大規模なデータセットと小規模なデータセットを分類する単純なしきい値はありません。ただし、モデルの実行が数分以内の場合は、相互検証に切り替える価値はあります。
または、相互検証を実行して、各実験のスコアが近いように見えるかどうかを確認することもできます。各実験で同じ結果が得られる場合は、単一の検証セットでおそらく十分です。
例えば
前のチュートリアルと同じデータを使用します。入力データをXにロードし、出力データをyにロードします。
次に、代入を使用して欠落値を埋めるパイプラインと、ランダムフォレストモデルを使用して予測を行うパイプラインを定義します。
パイプラインなしで相互検証を行うことは可能ですが、それは非常に困難です。パイプラインを使用すると、コードが非常に簡単になります。

scikit-learnからcross_val_score()関数を使用して相互検証スコアを取得します。折り畳み数はcvパラメーターで設定します。
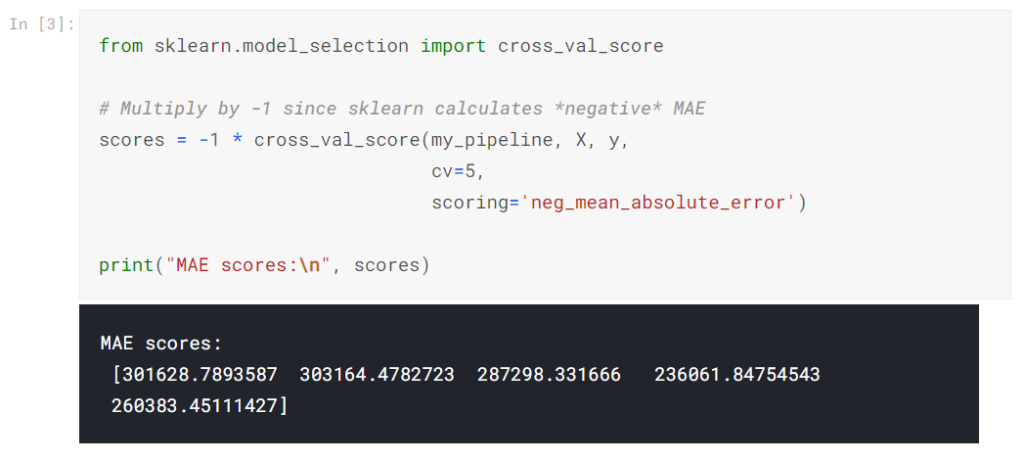
スコアリングパラメーターは、レポートするモデル品質の尺度を選択します。この場合、ネガティブの平均絶対誤差(MAE)を選択しました。 scikit-learnのドキュメントには、オプションのリストが表示されます。
ネガティブのMAEを指定するのは少し驚きです。 Scikit-learnには、すべての基準は数値が大きいほど良いという規則があります。ネガティブMAEは他の場所ではほとんど前例のないものですが、ここでネガティブを使用ことで、Scikit-learnの規則とあわせることができます。
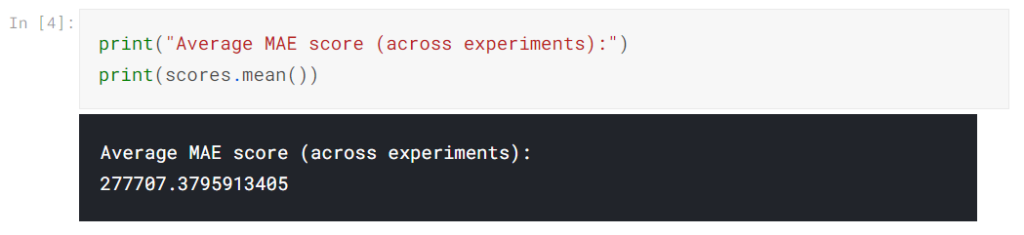
通常、代替モデルを比較するために、モデル品質の単一の測定値が必要です。したがって、実験全体の平均を取ります。
結論
相互検証を使用すると、モデルの品質をより正確に測定でき、コードをクリーンアップするという追加の利点があります。個別のトレーニングセットと検証セットを追跡する必要がなくなったことに注目してください。したがって、特に小さなデータセットの場合、これは良い改善です!
あなたの番
次の演習で新しいスキルを活用してください。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
