このチュートリアルでは、リーケージとは何か、そしてそれを防ぐ方法を学びます。 それを防ぐ方法がわからない場合、リーケージが頻繁に発生し、微妙で危険な方法でモデルを台無しにします。 したがって、これはデータサイエンティストを実践するための最も重要な概念の1つです。
はじめに
リーケージは、トレーニングデータにターゲットに関する情報が含まれている場合に発生しますが、モデルを予測に使用する場合、同様のデータは利用できません。これにより、トレーニングセット(場合によっては検証データ)で高いパフォーマンスが得られても、モデルの本番環境でのパフォーマンスが低下することがあります。
言い換えると、リーケージが、意思決定を開始するまでモデルが正確に見えても、その後モデルが非常に不正確になる原因になります。
リーケージには主に2つのタイプがあります。ターゲットの漏れとトレインテストの汚染です。
ターゲットリーケージ
ターゲットリーケージは、予測を行うときに利用できないデータが含まれている場合に発生します。機能が適切な予測を行うのに役立つかどうかだけでなく、データが利用可能になるタイミングまたは時系列の観点からターゲットリーケージを考慮することが重要です。
この例が役立ちます。誰が肺炎になるかを予測したいとします。生データの上位数行は次のようになります。
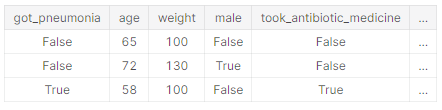
人々は肺炎にかかった後、回復するために抗生物質を服用します。生データはこれらの列の間に強い関係があることを示していますが、抗生物質を服用した(took_antibiotic_medicine)は、肺炎になった(got_pneumonia)が決定された後に頻繁に変更されます。これがターゲットリークです。
モデルでは、抗生物質を服用した(took_antibiotic_medicine)がFalseの人は、肺炎を患っていないことがわかります。検証データはトレーニングデータと同じソースから取得されるため、パターンは検証で繰り返され、モデルには優れた検証(または相互検証)スコアがあります。
しかし、現実の世界に展開すると、モデルは非常に不正確になります。なぜなら、将来の健康状態を予測する必要がある時点で、肺炎になってもまだ抗生物質を受け取っていないかもしれません。
この種のリンケージを防ぐには、目標値の実現後に更新(または作成)された変数を除外する必要があります。
トレインテスト汚染
トレーニングデータと検証データを注意深く区別しないと、別のタイプのリンケージが発生します。
検証は、モデルがこれまで考慮していなかったデータに対してどのように機能するかを測定するためのものであることを思い出してください。もし検証データが前処理の動作に影響を与える場合、このプロセスを何気なく破壊する可能性があります。このことが、トレインテスト汚染と呼ばれることがあります。
たとえば、scikit-learnのtrain_test_split関数を呼び出す前に、前処理(欠落した値に代入を当てはめるなど)を実行するとします。最終結果は?モデルの検証スコアが高く、信頼性が高い場合がありますが、モデルをデプロイして意思決定を行うと、パフォーマンスが低下します。
結局のところ、検証またはテストデータを予測に組み込んだため、新しいデータに一般化できない場合でも、その特定のデータでうまくいく可能性があります。より複雑な機能エンジニアリングを行うと、この問題はさらに微妙になります(そしてより危険になります)。
検証が単純なトレインテスト分割に基づいている場合は、前処理ステップのフィッティングを含む、あらゆるタイプのフィッティングから検証データを除外します。 scikit-learnパイプラインを使用すると、これは簡単になります。相互検証を使用する場合、パイプライン内で前処理を行うことがさらに重要です。
例えば
この例では、ターゲットの漏れを検出して除去する方法を学習します。
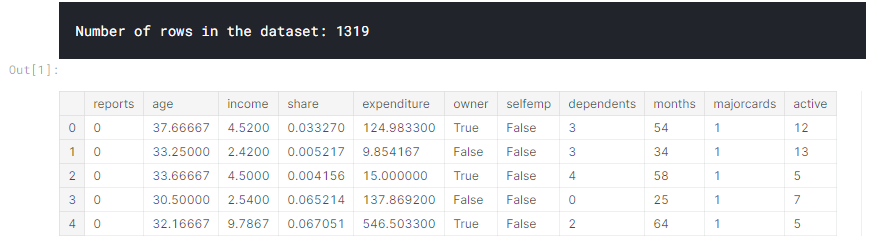
クレジットカードアプリケーションに関するデータセットを使用し、基本的なデータ設定コードをスキップします。最終結果として、各クレジットカードアプリケーションに関する情報がDataFrame Xに保存されます。これを使用して、シリーズyで受け入れられたアプリケーションを予測します。
これは小さなデータセットであるため、相互検証を使用して、モデルの品質を正確に測定します。
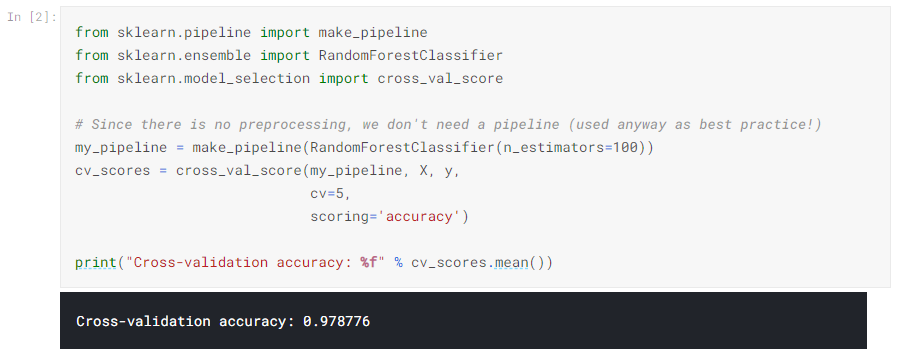
経験を積むと、98%の確率で正確なモデルを見つけることは非常にまれであることがわかります。それは起こりますが、ターゲットのリンケージについてデータをより綿密に検査する必要があることは十分にまれです。
データの概要は次のとおりです。データタブにもあります。
- カード:
1:クレジットカードの申し込みが受け付けられた場合
0:受け入れられなかった場合 - レポート:
主要な信用に関するネガティブな記録の数 - 年齢:
何歳何か月 - 収入:
年収(10,000で割る) - シェア:
年間収入に対する毎月のクレジットカード支出の比率 - 支出:
平均月間クレジットカード支出 - 所有者:
1:家を所有している場合
0:家賃の場合 - selfempl:
1:自営業の場合
0:その他 - 扶養家族:
1+扶養家族の数 - 月:
現在の住所に住んでいる月 - majorcards:
保持されている主要なクレジットカードの数 - アクティブ:
アクティブなクレジットアカウントの数
いくつかの変数は疑わしいように見えます。たとえば、支出とはこのカードの支出を意味しますか?それとも今まで使用したカードでの支出を指しますか?この時点で、基本的なデータ比較が非常に役立ちます。

上に示したように、カードを受け取っていない人は誰も支出がありませんでしたが、カードを受け取った人の2%だけが支出がありませんでした。私たちのモデルが高精度であるように見えたのは当然のことです。しかし、これはターゲットリーケージの場合でもあるようです。そこでは、支出はおそらく彼らが申請したカードへの支出を意味します。
シェアは支出によって部分的に決定されるため、それも除外する必要があります。変数activeとmajorcardsは少し明確ではありませんが、説明から、それらは関係しているように思えます。ほとんどの場合、データを作成した人を追跡して詳細を調べることができない場合は、後悔するよりも安全である方がよいでしょう。
次のように、ターゲットリーケージのないモデルを実行します。
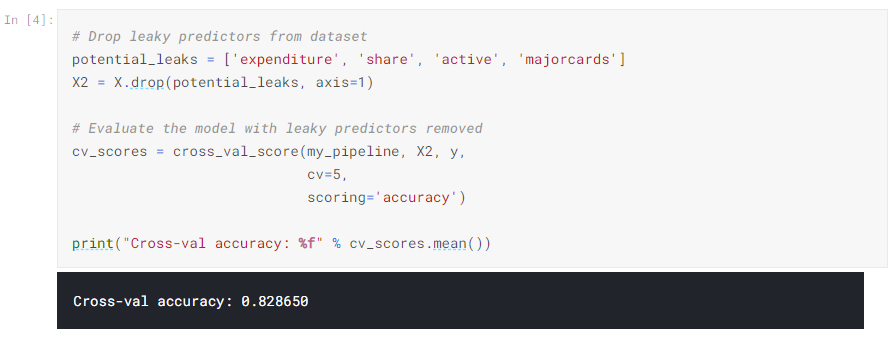
この精度はかなり低く、がっかりするかもしれません。ただし、新しいアプリケーションで使用した場合、約80%の確率で正しいと予想できますが、リーケージモデルはそれよりもはるかに悪い結果になる可能性があります(交差検定での見かけのスコアが高いにもかかわらず)。
結論
多くのデータサイエンスアプリケーションでは、リーケージは数百万ドルの間違いになる可能性があります。トレーニングデータと検証データを注意深く分離することで、トレインテストの汚染を防ぐことができ、パイプラインはこの分離の実装に役立ちます。同様に、注意、常識、およびデータ探索の組み合わせは、ターゲットの漏洩を特定するのに役立ちます。
次はすることは?
これはまだ抽象的なように見えるかもしれません。この演習の例を通して、リーケージの漏れとトレインテストの汚染を特定するスキルを身に付けてください。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
