はじめに
まず、機械学習モデルの仕組みとその使用方法の概要から始めます。以前に統計モデリングや機械学習を行ったことがある場合、これは基本的なことだと感じるかもしれませんが、心配しないでください。すぐに強力なモデルの構築に進みます。
このマイクロコースでは、次のシナリオを実行しながらモデルを作成します。
あなたのいとこは何百万ドルも不動産を投機してきました。彼はあなたがデータサイエンスに興味があるため、あなたとのビジネスパートナーになることを申し出ました。彼はお金を供給し、あなたはさまざまな家の価値を予測するモデルを供給します。
あなたはいとこに、今までどのように不動産の価値を予測したかを尋ねたところ、彼はただの直感だと言います。しかし、さらに質問すると、彼は過去に見た家から価格パターンをみつけ、それらのパターンを使用して、検討中の新しい家の予測を行っていることがわかりました。
機械学習も同じように機能します。私たちはデシジョンツリーと呼ばれるモデルから始めます。より正確な予測を提供するより洗練されたモデルがありますが、デシジョンツリーは理解しやすく、データサイエンスの最良なモデルの基本的な構成要素になります。
簡単にするために、可能な限り単純なデシジョンツリーから始めます。

※家に2つ以上の寝室がありますか?
上図は家を2つのカテゴリーだけに分けます。 検討中の住宅の予測価格は、同じような住宅の過去の平均価格です。
データを使用して、家を2つのグループに分割する方法を決定し、次に各グループの予測価格を決定します。 データからパターンをキャプチャするこのステップは、モデルのフィッティングまたはトレーニングと呼ばれます。 モデルの適合に使用されるデータは、トレーニングデータと呼ばれます。
モデルがどのように適合しているか(データを分割する方法など)の詳細は、後で使用するために保存するのに十分なほど複雑です。 モデルが適合したら、それを新しいデータに適用して、追加の住宅の価格を予測できます。
デシジョンツリーの改善
次の2つのデシジョンツリーのうち、不動産トレーニングデータのフィッティングから生じる可能性が高いのはどれですか?
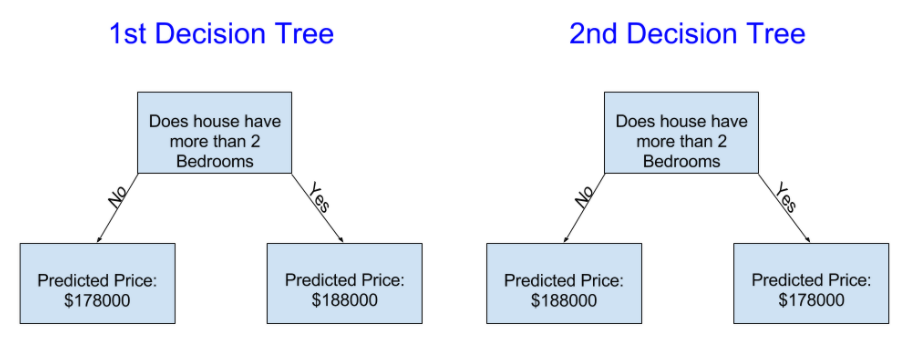
左側のデシジョンツリー(デシジョンツリー1)は、寝室が多い家は寝室が少ない家よりも高い価格で販売される傾向があるという現実を捉えているため、おそらくより理にかなっています。 このモデルの最大の欠点は、バスルームの数、ロットサイズ、場所など、住宅価格に影響を与えるほとんどの要因をキャプチャできないことです。
より多くの「分割」を持つツリーを使用して、より多くの要素をキャプチャできます。 これらは「より深い」ツリーと呼ばれます。 各家の区画の合計サイズも考慮したデシジョンツリーは、次のようになります。
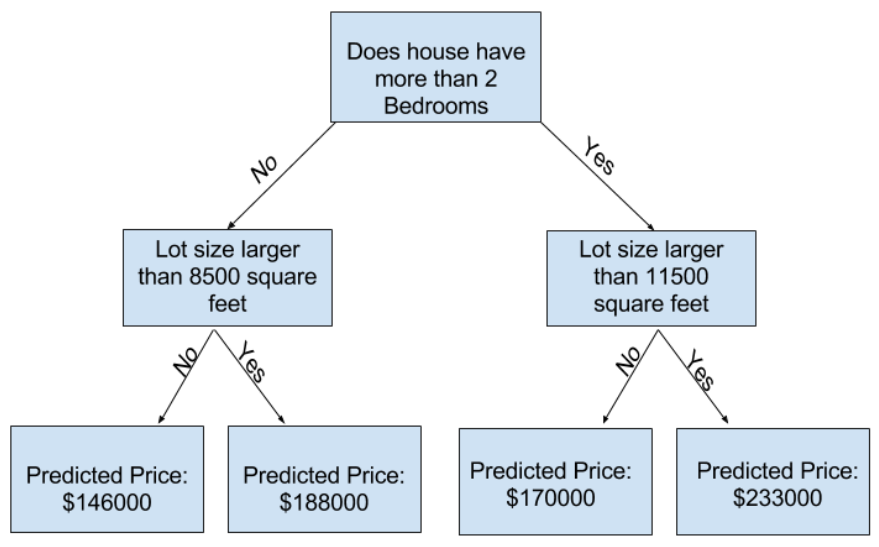
決定木をトレースし、常にその家の特性に対応するパスを選択することで、家の価格を予測します。 家の予測価格はツリーの一番下にあります。 予測を行う下部のポイントはリーフと呼ばれます。
葉の分割と値はデータによって決定されるので、作業するデータを確認するときが来ました。
Continue
もっと具体的にしましょう。 それはあなたのデータを調べる時です。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
