この演習では、データファイルを読み取り、データに関する統計を理解する能力をテストします。
後の演習では、データをフィルタリングし、機械学習モデルを構築し、モデルを繰り返し改善する手法を適用します。
コースの例では、メルボルンのデータを使用しています。 これらの手法を自分で適用できるようにするには、新しいデータセットに適用する必要があります(アイオワの住宅価格を使用)。
演習では、「ノートブック」コーディング環境を使用します。 ノートブックに慣れていない方のために、90秒の紹介ビデオを用意しています。
演習
次のセルを実行してコードチェックを設定します。これにより、作業が進むにつれて検証されます。

実行後

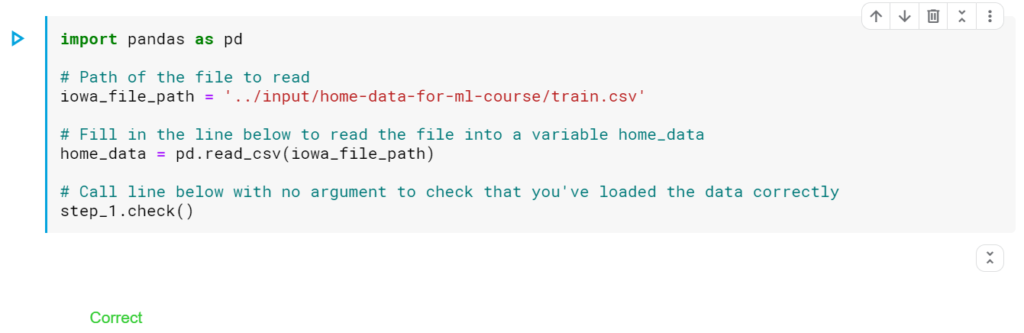
ステップ1:データをロードする
アイオワデータファイルをhome_dataと呼ばれるPandasDataFrameに読み込みます。

実行後

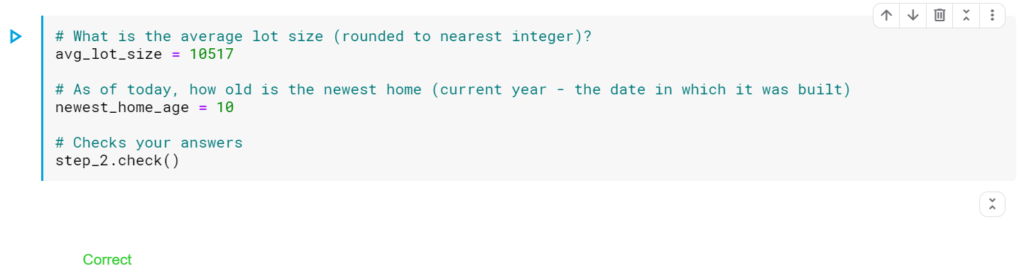
ステップ2:データを確認する
学習したコマンドを使用して、データの要約統計量を表示します。 次に、変数を入力して次の質問に答えます


実行後

データについて考える
あなたのデータの最新の家はそれほど新しいものではありません。 これに関するいくつかの潜在的な説明:
1.彼らはこのデータが収集された新しい家を建てていません。
2.データはずっと前に収集されました。 データ公開後に建てられた家は表示されません。
理由が上記の説明#1である場合、それはこのデータを使用して構築するモデルへの信頼に影響しますか? それが理由#2である場合はどうですか?
どの説明がより妥当であるかを確認するために、どのようにデータを掘り下げることができますか?
このディスカッションスレッドをチェックして、他の人の考えを確認したり、アイデアを追加したりしてください。
次に進もう
これで、最初の機械学習モデルの準備が整いました。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
