要約
モデルを作成しました。 この演習では、モデルがどれだけ優れているかをテストします。
以下のセルを実行して、前の演習で中断したコーディング環境をセットアップします。

実行結果
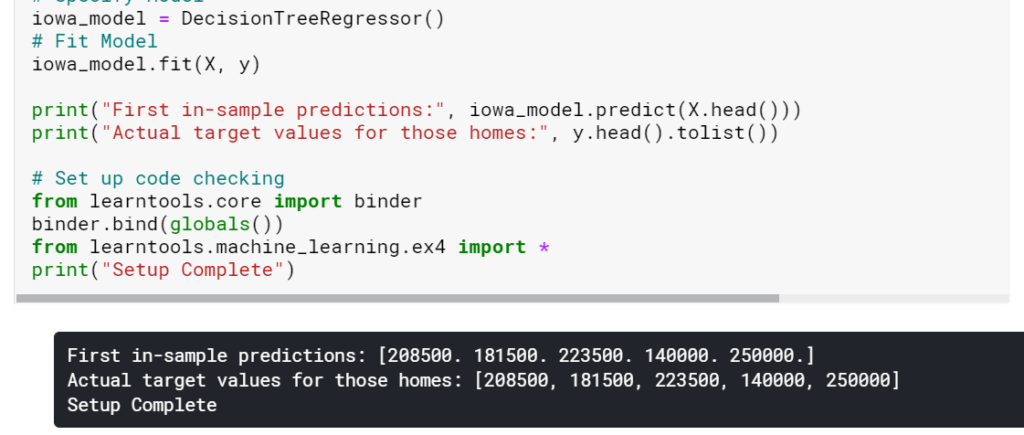
演習
ステップ1:データを分割する
train_test_split関数を使用して、データを分割します。 引数random_state = 1を指定して、チェック関数がコードを検証するときに何を期待するかを認識できるようにします。 フィーチャーはDataFrameXにロードされ、ターゲットはyにロードされることを思い出してください。

実行結果


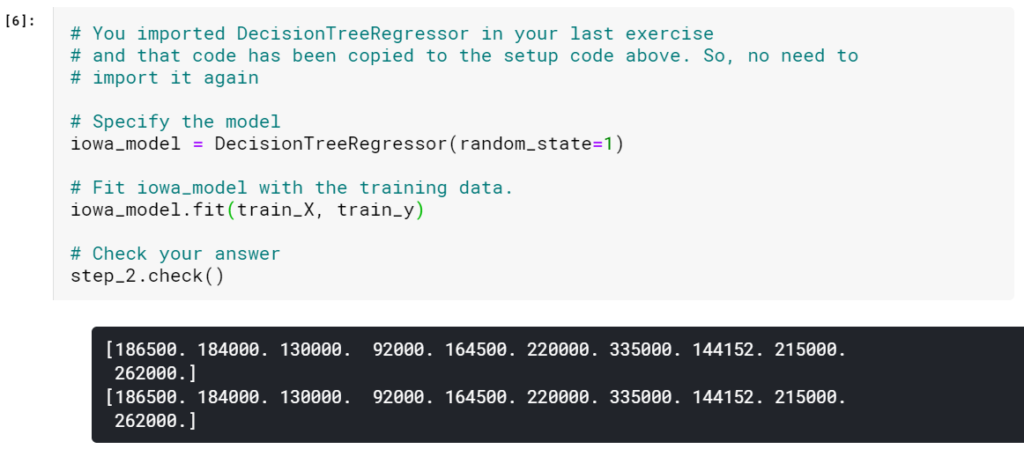
ステップ2:モデルを指定して適合させる
DecisionTreeRegressorモデルを作成し、関連するデータに適合させます。 モデルを作成するときに、random_stateをもう一度1に設定します。

実行結果

ステップ3:検証データを使用して予測を行う

実行結果


検証データから予測と実際の値を調べます。

実行結果
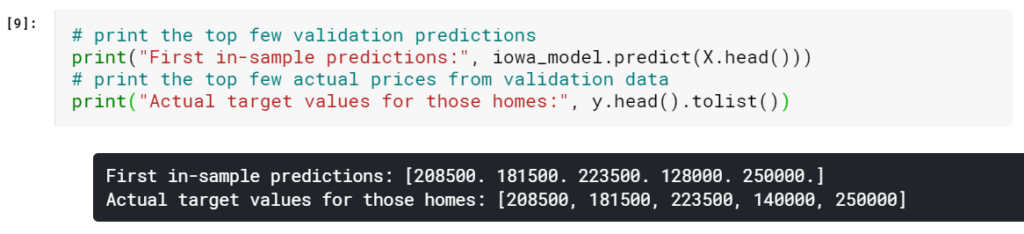
サンプル内予測(このページの一番上のコードセルの後に印刷されます)で見たものとは異なることに気づきましたか。
検証予測がサンプル内(またはトレーニング)予測と異なる理由を覚えていますか? これは前のレッスンからの重要なアイデアです。
ステップ4:検証データの平均絶対誤差を計算する

実行結果
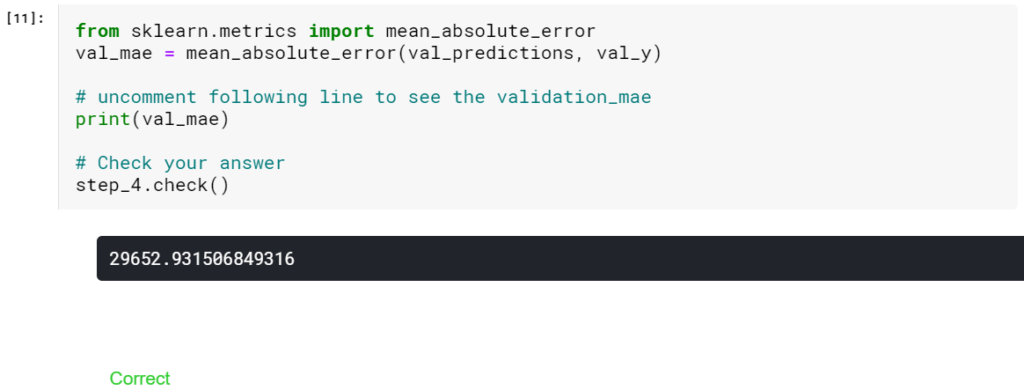

それはMAEはいいですか? アプリケーション全体に適用される適切な値についての一般的な規則はありません。 ただし、次のステップでこの数値を使用(および改善)する方法を説明します。
次に進もう
過適合と過剰適合の準備ができています。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
