このステップの最後に、学習不足と過学習の概念を理解し、これらのアイデアを適用してモデルをより正確にすることができます。
さまざまなモデルで実験する
モデルの精度を測定する信頼できる方法ができたので、代替モデルを試して、どれが最良の予測を与えるかを確認できます。 しかし、モデルにはどのような選択肢がありますか?
scikit-learnのドキュメントで、デシジョンツリーモデルには多くのオプションがあることがわかります(長い間必要なものよりも多くのオプションがあります)。 最も重要なオプションは、ツリーの深さを決定します。 このマイクロコースの最初のレッスンから、ツリーの深さは、予測に至る前に分割する回数の尺度であることを思い出してください。 これは比較的浅いツリーです。
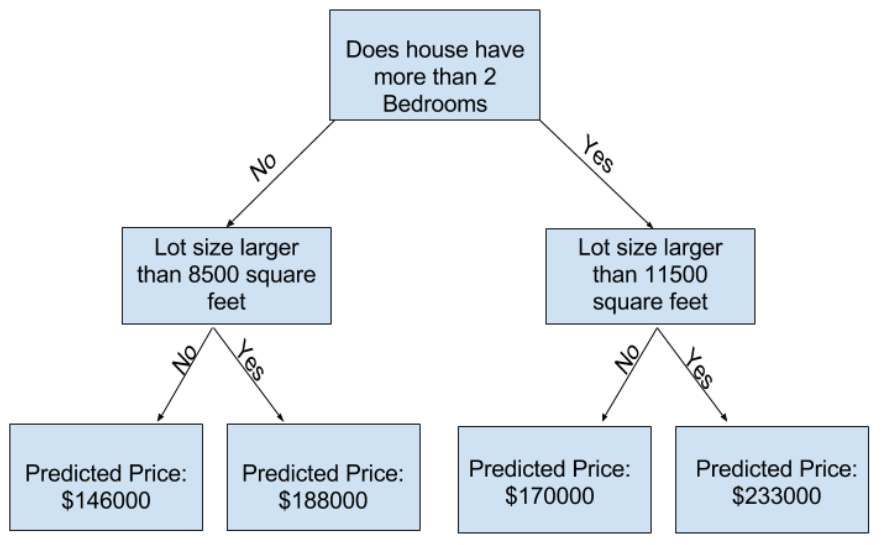
実際には、ツリーがトップレベル(すべての家)とリーフの間に10個の分割があることは珍しいことではありません。ツリーが深くなるにつれて、データセットは家の数が少ないリーフにスライスされます。ツリーの分割が1つしかない場合は、データを2つのグループに分割します。各グループが再び分割されると、家のグループが4つ得られます。それらのそれぞれを再度分割すると、8つのグループが作成されます。各レベルで分割を追加してグループの数を2倍にし続けると、10レベルに到達するまでに210の家のグループができます。それは1024枚のリーフです。
家を多くのリーフに分けると、各リーフの家は少なくなります。家が非常に少ないリーフは、それらの家の実際の値に非常に近い予測を行いますが、新しいデータについては非常に信頼性の低い予測を行う可能性があります(各予測は少数の家のみに基づいているため)。
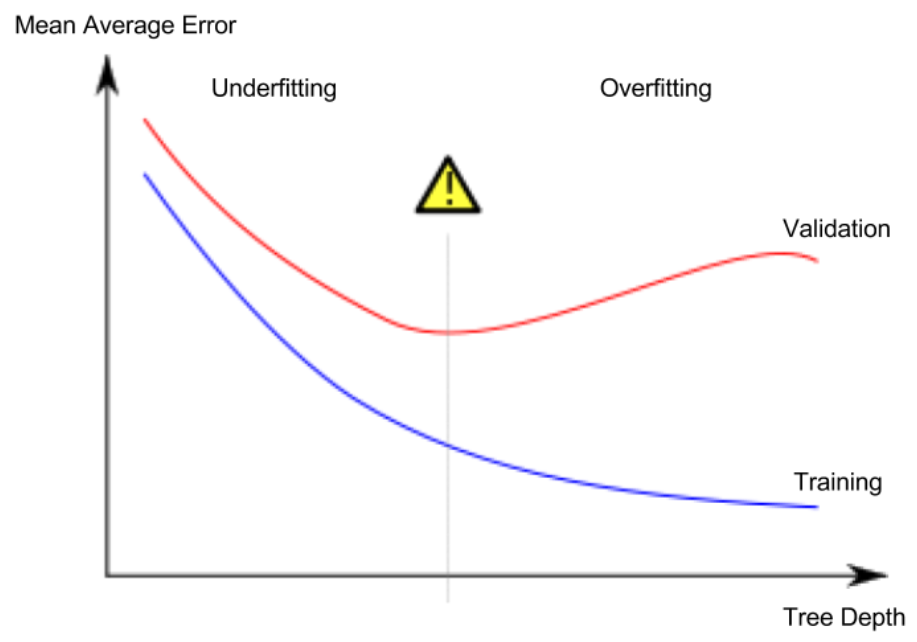
これは過学習と呼ばれる現象であり、モデルはトレーニングデータとほぼ完全に一致しますが、検証やその他の新しいデータでは不十分です。反対に、ツリーを非常に浅くすると、家が非常に明確なグループに分割されることはありません。
極端な場合、ツリーが家を2つまたは4つに分割する場合でも、各グループにはさまざまな家があります。結果として得られる予測は、トレーニングデータであっても、ほとんどの住宅ではるかに遠い可能性があります(同じ理由で、検証でも問題が発生します)。モデルがデータ内の重要な区別やパターンをキャプチャできないため、トレーニングデータでもパフォーマンスが低下する場合、これは学習不足と呼ばれます。
検証データから推定する新しいデータの精度に関心があるため、学習不足と過学習の間のスイートスポットを見つけたいと考えています。視覚的には、(赤の)検証曲線の最低点が必要です。
例
ツリーの深さを制御する方法はいくつかあり、多くの場合、ツリーを通る一部のルートの深さを他のルートよりも大きくすることができます。 ただし、max_leaf_nodes引数は、過学習と学習不足を制御するための非常に賢明な方法を提供します。 モデルに作成できるリーフが多いほど、上のグラフの学習不足領域から過学習領域に移動します。
ユーティリティ関数を使用して、max_leaf_nodesのさまざまな値からのMAEスコアを比較できます。
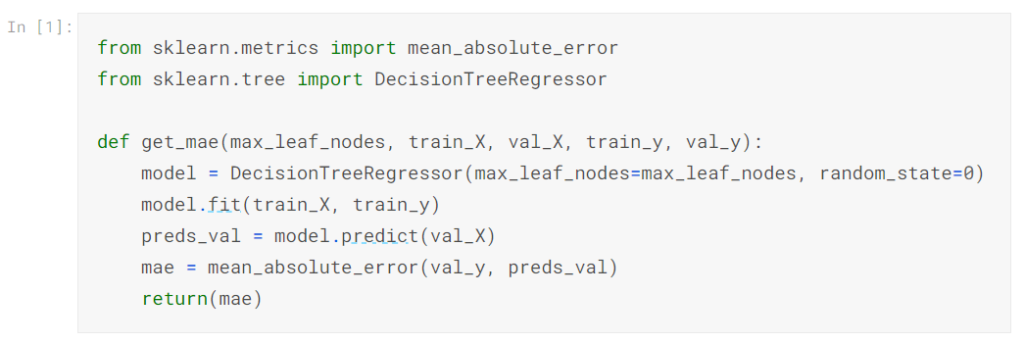
データは、すでに見た(そしてすでに書いた)コードを使用してtrain_X、val_X、train_y、val_yにロードされます。
forループを使用して、max_leaf_nodesのさまざまな値で構築されたモデルの精度を比較できます。
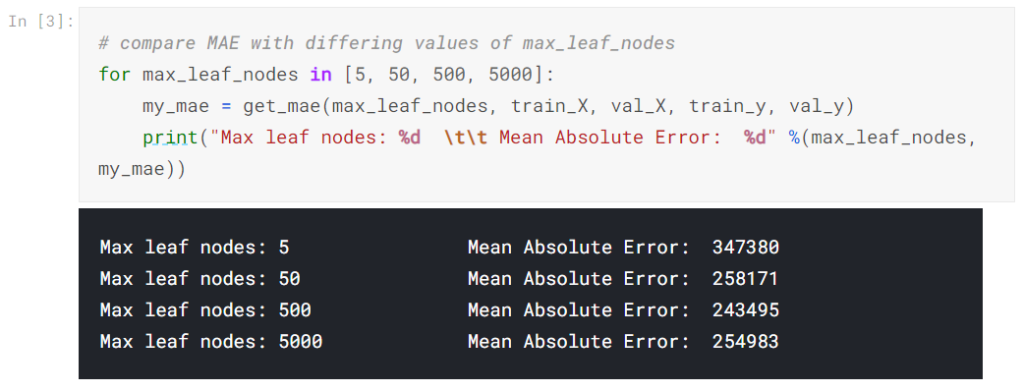
リストされているオプションのうち、500が最適なリーフの数です。
結論
要点は次のとおりです。モデルは次のいずれかに苦しむ可能性があります。
過学習:将来再発しない偽のパターンをキャプチャし、予測の精度を低下させる
学習不足:関連するパターンのキャプチャに失敗し、予測の精度を低下させる
モデルトレーニングでは使用されない検証データを使用して、候補モデルの精度を測定します。 これにより、多くの候補モデルを試して、最良のモデルを維持できます。
あなたの番です
以前に作成したモデルを最適化してみてください。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
