要約
最初のモデルを作成しました。次に、ツリーのサイズを最適化して、より適切な予測を行います。 このセルを実行して、前の手順で中断したコーディング環境をセットアップします。
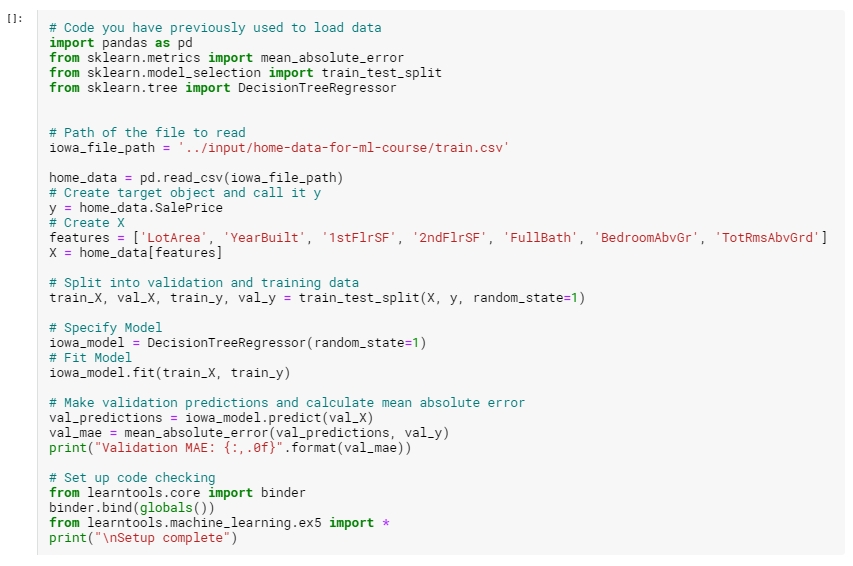
実行結果
演習
関数get_maeを自分で書くことができます。 今のところ、それを供給します。 これは、前のレッスンで読んだ関数と同じです。 下のセルを実行するだけです。

ステップ1:異なるツリーサイズを比較する
可能な値のセットからmax_leaf_nodesに対して次の値を試行するループを記述します。
max_leaf_nodesの各値でget_mae関数を呼び出します。 データで最も正確なモデルを提供するmax_leaf_nodesの値を選択できるように、出力を保存します。
実行結果


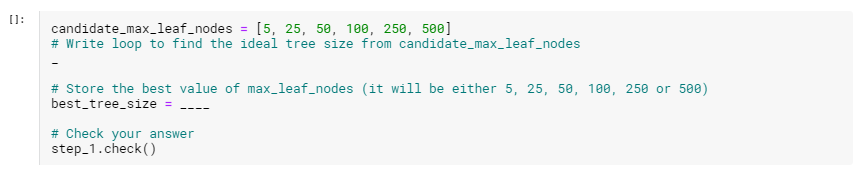
ステップ2:すべてのデータを使用してモデルを適合させる
あなたは最高のツリーのサイズを知っています。 このモデルを実際にデプロイする場合は、すべてのデータを使用し、そのツリーサイズを維持することで、モデルをさらに正確にすることができます。 つまり、モデリングに関するすべての決定を行ったので、検証データを保持する必要はありません。

実行結果

このモデルを調整し、結果を改善しました。 ただし、最新の機械学習標準ではあまり洗練されていないディシジョンツリーモデルを引き続き使用しています。 次のステップでは、ランダムフォレストを使用してモデルをさらに改善する方法を学びます。
次に進もう
ランダムフォレストの準備ができました。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
