機械学習入門コースの最後の演習では、Kaggleコンテストに提出する方法を学びました。 ただし、部分的に完成したコードを含むノートブックが提供されたため、一部の作業はすでに完了しています。
このチュートリアルでは、Kaggleコンテストへの提出物の作成を開始するために(最初から!)使用できる完全なワークフローについて説明します。 例としてタイタニックの競争を使用します。
パート1:始めましょう
このセクションでは、コンテストの詳細を学び、最初の提出を行います。
コンテストに参加してください!
最初にすることは、コンテストに参加することです! まだ行っていない場合は、コンテストページで新しいウィンドウを開き、[コンテストに参加]ボタンをクリックします。 ([コンテストに参加]ボタンの代わりに[予測を送信]ボタンが表示されている場合は、すでにコンテストに参加しているので、再度参加する必要はありません。)
これにより、ルールの承認ページに移動します。 参加するには、競技規則に同意する必要があります。 これらのルールは、1日に作成できる提出の数、最大チームサイズ、およびその他のコンテスト固有の詳細を管理します。 次に、「理解して受け入れる」をクリックして、競技規則を遵守することを示します。
挑戦
競争は単純です。タイタニック号の乗客データ(名前、年齢、チケットの価格など)を使用して、誰が生き残り、誰が死ぬかを予測してください。
データ
コンテストデータを確認するには、コンテストページの上部にある[データ]タブをクリックします。 次に、下にスクロールしてファイルのリストを見つけます。
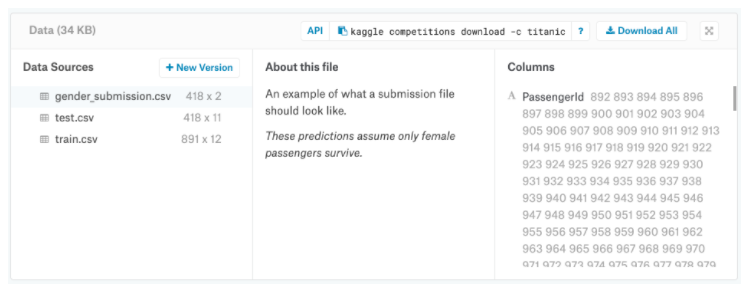
データには、(1)train.csv、(2)test.csv、および(3)gender_submission.csvの3つのファイルがあります。
(1)train.csv
train.csvには、搭乗している乗客のサブセットの詳細が含まれています(正確には、891人の乗客-各乗客はテーブル内の異なる行を取得します)。 このデータを調査するには、[データソース]列(画面の左側)の下にあるファイルの名前をクリックします。 これを実行すると、すべての列名(およびそれらに含まれる内容の簡単な説明)が画面の右側の[列]見出しの下に一覧表示されます。
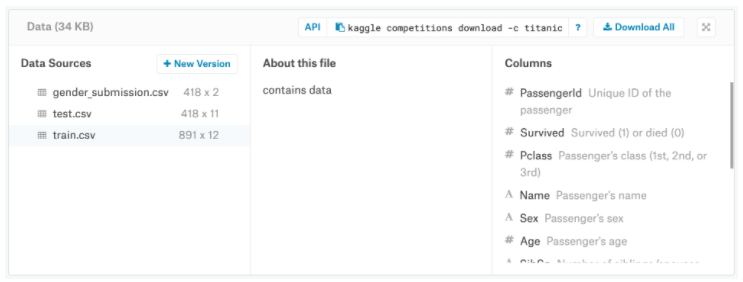
すべてのデータを同じウィンドウで表示できます。
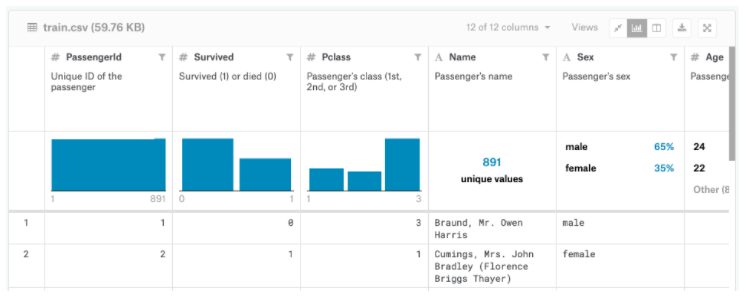
2番目の列(「Survived」)の値を使用して、各乗客が生き残ったかどうかを判断できます。
- 「1」の場合、乗客は生き残った。
- 「0」の場合、乗客は死亡しました。
たとえば、train.csvにリストされている最初の乗客は、オーウェンハリスブラウン氏です。 彼がタイタニックで亡くなったとき、彼は22歳でした。
(2)test.csv
train.csvにあるパターンを使用して、(test.csvにある)他の418人の乗客が生き残ったかどうかを予測する必要があります。
test.csv([データソース]列の下)をクリックして、その内容を確認します。 test.csvには「Survived」列がないことに注意してください。この情報は非表示になっています。これらの非表示の値をどれだけうまく予測できるかによって、コンテストでのスコアがどれだけ高くなるかが決まります。
(3) gender_submission.cs
予測を構造化する方法を示す例として、gender_submission.csvファイルが提供されています。 それは、すべての女性の乗客が生き残り、すべての男性の乗客が死亡したと予測しています。 生存に関するあなたの仮説はおそらく異なり、それは異なる提出ファイルにつながるでしょう。 ただし、このファイルと同様に、提出物には次のものが必要です。
- test.csvの各乗客のIDを含む「PassengerId」列。
- 「Survived」列(作成します!)には、乗客が生き残ったと思われる行に「1」が表示され、乗客が死亡したと予測される行に「0」が表示されます。
あなたの最初の提出
ベンチマークとして、gender_submission.csvファイルをダウンロードしてコンテストに提出します。 ファイル名の右側にあるダウンロードリンクをクリックすることから始めます。

これにより、ファイルがコンピューターにダウンロードされます。 次に:
- コンテストページ右上の青い「予測送信」ボタンをクリックしてください。 (このボタンは、[コンテストに参加]ボタンがあった場所に表示されます。)
- 「ステップ1:提出ファイルのアップロード」までスクロールダウンします。 ダウンロードしたファイルをアップロードします。 次に、青い[送信する]ボタンをクリックします。
数秒で、あなたの提出物が採点され、リーダーボードにスポットが表示されます。 次に、この最初の提出を上回る方法を説明します。
パート2:コーディング環境
このセクションでは、予測を改善するために独自の機械学習モデルをトレーニングします。
ノートブック
最初に行うことは、すべてのコードを保存するKaggleNotebookを作成することです。 Kaggle Notebooksを使用すると、コンピューターに何もインストールしなくても、コードをすばやく作成して実行できます。 (ディープラーニングに興味がある場合は、無料のGPUおよびTPUアクセスも提供しています!)
コンテストページの[Notebooks]タブをクリックすることから始めます。 次に、「New Notebook」をクリックします。
ノートブックの読み込みには数秒かかります。 左上隅に、ノートブックの名前(「kernel2daed3cd79」など)が表示されます。

名前をクリックすると編集できます。 「タイタニック入門」など、よりわかりやすいものに変更してください。

コードの最初の行
新しいノートブックを起動すると、コードを保存するための2つの灰色のボックスがあります。 これらの灰色のボックスを「コードセル」と呼びます。
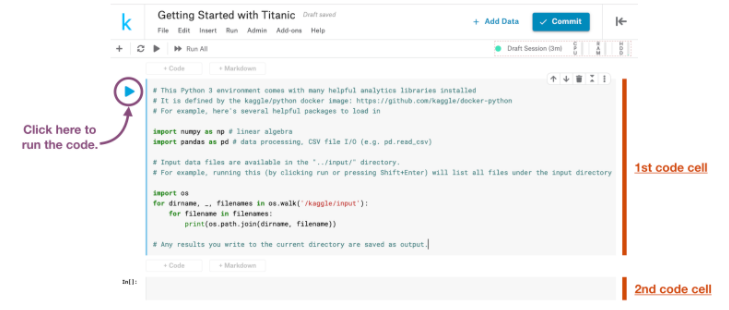
最初のコードセルには、すでにいくつかのコードが含まれています。 このコードを実行するには、コードセルにカーソルを置きます。 (カーソルが正しい位置にある場合、灰色のボックスの左側に青い縦線が表示されます。)次に、再生ボタン(青い線の左側に表示されます)を押すか、[Shift]を押します。 ] + [Enter]キーボードで。
コードが正常に実行されると、3行の出力が返されます。 以下に、実行したのと同じコードと、ノートブックに表示されるはずの出力を示します。
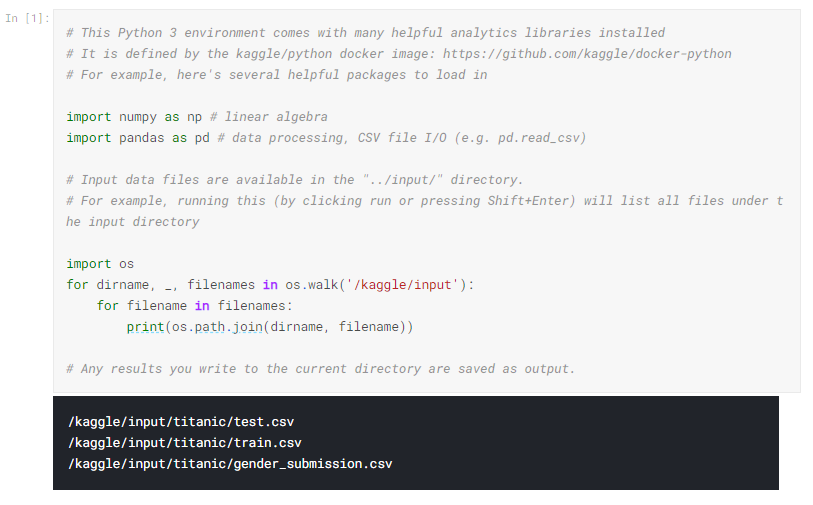
これにより、競合データが保存されている場所がわかり、ファイルをノートブックにロードできます。 次にそれを行います。
データをロードする
ノートブックの2番目のコードセルが、ファイルの場所とともに3行の出力の下に表示されます。

以下の2行のコードを2番目のコードセルに入力します。 次に、完了したら、青い再生ボタンをクリックするか、[Shift] + [Enter]を押します。
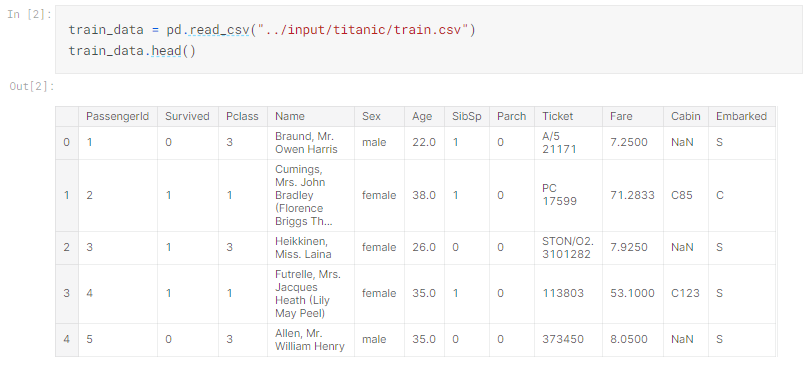
コードは、train.csvのテーブルの最初の5行に対応する上記の出力を返す必要があります。チュートリアルに進む前に、この出力をノートブックに表示することが非常に重要です。
コードでこの出力が生成されない場合は、コードが上記の2行と同じであることを再確認してください。また、[Shift] + [Enter]を押す前に、カーソルがコードセルにあることを確認してください。
今書いたコードはPythonプログラミング言語です。 pandas(pdと略記)と呼ばれるPythonの「モジュール」を使用して、train.csvファイルからノートブックにテーブルをロードします。これを行うには、ファイルの場所(/kaggle/input/titanic/train.csv)をプラグインする必要がありました。
Python(およびパンダ)にまだ精通していない場合、コードは意味をなさないはずですが、心配しないでください!このチュートリアルのポイントは、(すばやく!)コンテストに最初に提出することです。チュートリアルの最後に、学習を継続するためのリソースを提案します。
この時点で、ノートブックには少なくとも3つのコードセルが必要です。

以下のコードをノートブックの3番目のコードセルにコピーして、test.csvファイルの内容を読み込みます。 再生ボタンをクリックする(または[Shift] + [Enter]を押す)ことを忘れないでください!
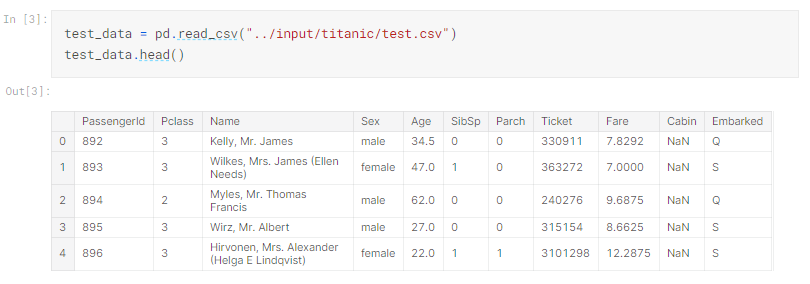
前と同じように、続行する前に、ノートブックに上記の出力が表示されていることを確認してください。
すべてのコードが正常に実行されると、すべてのデータ(train.csvおよびtest.csv内)がノートブックにロードされます。 (上記のコードは、各テーブルの最初の5行のみを示していますが、すべてのデータがあります-train.csvの891行すべてとtest.csvの418行すべてです!)
パート3:スコアを向上させる
test.csvの乗客が生き残ったかどうかを予測するのに役立つ、train.csvのパターンを見つけたいという目標を忘れないでください。
ソートするデータが非常に多い場合、最初はパターンを探すのに圧倒されるかもしれません。 それで、簡単に始めましょう。
パターンを探る
性別_submission.csvのサンプル送信ファイルは、すべての女性の乗客が生き残った(そしてすべての男性の乗客が死亡した)ことを前提としていることに注意してください。
これは合理的な最初の推測ですか? このパターンがデータ(train.csv内)に当てはまるかどうかを確認します。
以下のコードを新しいコードセルにコピーします。 次に、セルを実行します。
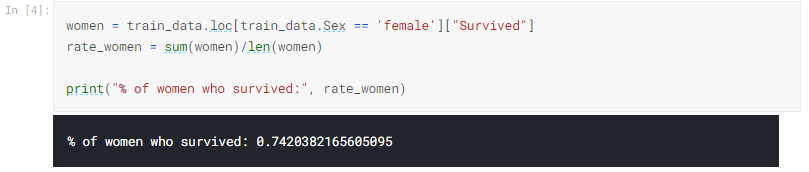
先に進む前に、コードが上記の出力を返すことを確認してください。 上記のコードは、生き残った女性の乗客(train.csv内)の割合を計算します。
次に、別のコードセルで以下のコードを実行します。
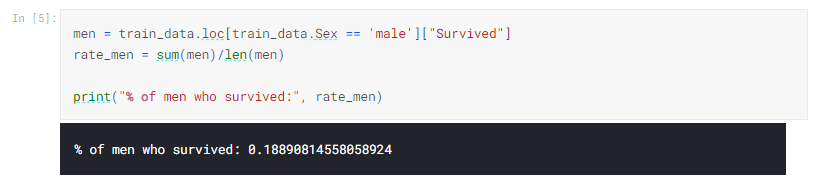
上記のコードは、生き残った男性の乗客(train.csv内)の割合を計算します。
このことから、乗船している女性のほぼ75%が生き残ったのに対し、男性の19%だけがそれについて話すために生きていたことがわかります。 性別は生存の非常に強力な指標であるように思われるので、gender_submission.csvの送信ファイルは悪い最初の推測ではなく、それが適度にうまく機能したことは理にかなっています!
しかし、結局のところ、この性別に基づく提出は、単一の列のみに基づいて予測を行います。 ご想像のとおり、複数の列を検討することで、より多くの情報に基づいた予測が得られる可能性のある、より複雑なパターンを見つけることができます。 一度に複数の列を検討することは非常に難しいため(または、多くの異なる列で考えられるすべてのパターンを同時に検討するのに長い時間がかかるため)、機械学習を使用してこれを自動化します。
最初の機械学習モデル
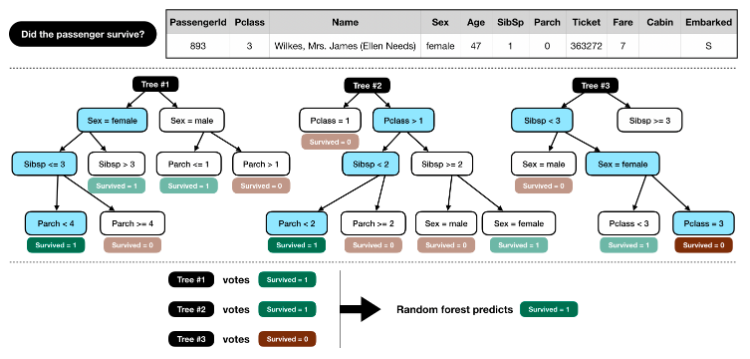
ランダムフォレストモデルを作成します。 このモデルは、各乗客のデータを個別に検討し、その個人が生き残ったかどうかを投票する複数の「ツリー」(下の写真には3つのツリーがありますが、100を構築します!)で構成されています。 次に、ランダムフォレストモデルが民主的な決定を下します。投票数が最も多い結果が勝ちます。
以下のコードセルは、データの4つの異なる列(「Pclass」、「Sex」、「SibSp」、および「Parch」)でパターンを検索します。 test.csvで乗客の予測を生成する前に、train.csvファイルのパターンに基づいてランダムフォレストモデルでツリーを構築します。 このコードは、これらの新しい予測をCSVファイルmy_submission.csvに保存します。
このコードをノートブックにコピーし、新しいコードセルで実行します。
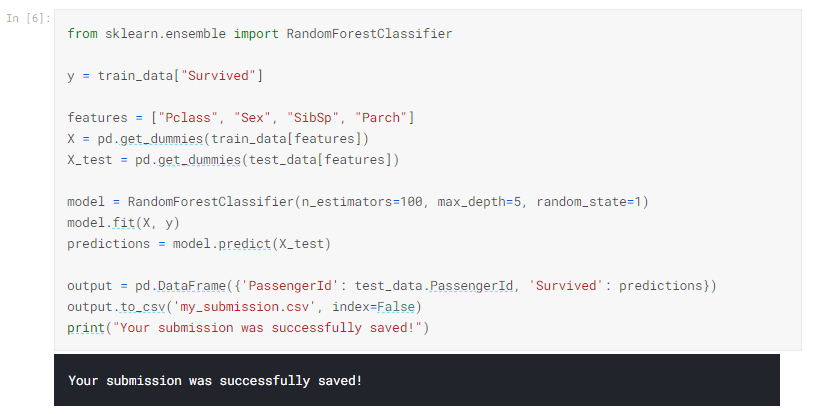
先に進む前に、ノートブックが上記と同じメッセージを出力することを確認してください(送信は正常に保存されました!)。
繰り返しますが、このコードが意味をなさなくても心配しないでください! ここでは、予測を生成して送信する方法に焦点を当てます。
準備ができたら、ノートブックの右上隅にある青い[Save Version]ボタンをクリックします。 これにより、ポップアップウィンドウが生成されます。
- [Save and Run All]オプションが選択されていることを確認してから、青い[Save]ボタンをクリックします。
- これにより、ノートブックの左下隅にウィンドウが生成されます。 実行が終了したら、[Save Version]ボタンの右側にある番号をクリックします。 これにより、画面の右側にバージョンのリストが表示されます。 最新バージョンの右側にある省略記号(…)をクリックし、[Open in Viewer]を選択します。
- 画面右側の[Output]タブをクリックします。 次に、[Submit to Competition]ボタンをクリックして、結果を送信します。
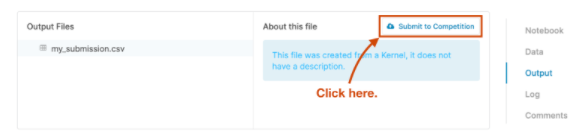
ファイルが正常に送信されると、リーダーボードを上に移動したことを示すメッセージが表示されます。 すごい仕事!
パート4:学び続けてください!
機械学習入門コースでランダムフォレストについて学んだことを使用して、さらに優れた予測を生成できますか?
より高度なテクニックについては、中級機械学習コースをご覧ください。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |

