このチュートリアルでは、パイプラインを使用してモデリングコードをクリーンアップする方法を学習します。
はじめに
パイプラインは、データの前処理とモデリングコードを整理するための簡単な方法です。具体的には、パイプラインは前処理とモデリングのステップをバンドルしているため、バンドル全体を単一のステップであるかのように使用できます。
多くのデータサイエンティストはパイプラインなしでモデルをハッキングしますが、パイプラインにはいくつかの重要な利点があります。それらが含まれます:
- よりクリーンなコード:前処理の各ステップでのデータのアカウンティングは煩雑になる可能性があります。パイプラインを使用すると、各ステップでトレーニングデータと検証データを手動で追跡する必要がありません。
- バグの減少:ステップを誤って適用したり、前処理ステップを忘れたりする機会が少なくなります。
- 生産が容易:モデルをプロトタイプから大規模に展開可能なものに移行するのは驚くほど難しい場合があります。ここでは、関連する多くの懸念事項については説明しませんが、パイプラインが役立ちます。
- モデル検証のその他のオプション:次のチュートリアルで、相互検証について説明する例を示します。
例えば
前のチュートリアルと同様に、MelbourneHousingデータセットを使用します。
データの読み込み手順には焦点を当てません。代わりに、X_train、X_valid、y_train、およびy_validにトレーニングおよび検証データが既にある時点にいると想像できます。
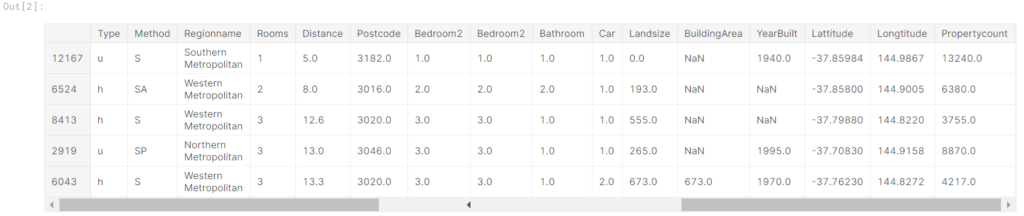
以下のhead()メソッドを使用してトレーニングデータを確認します。データには、カテゴリデータと値が欠落している列の両方が含まれていることに注意してください。パイプラインを使用すると、両方に簡単に対処できます。

3つのステップで完全なパイプラインを構築します。
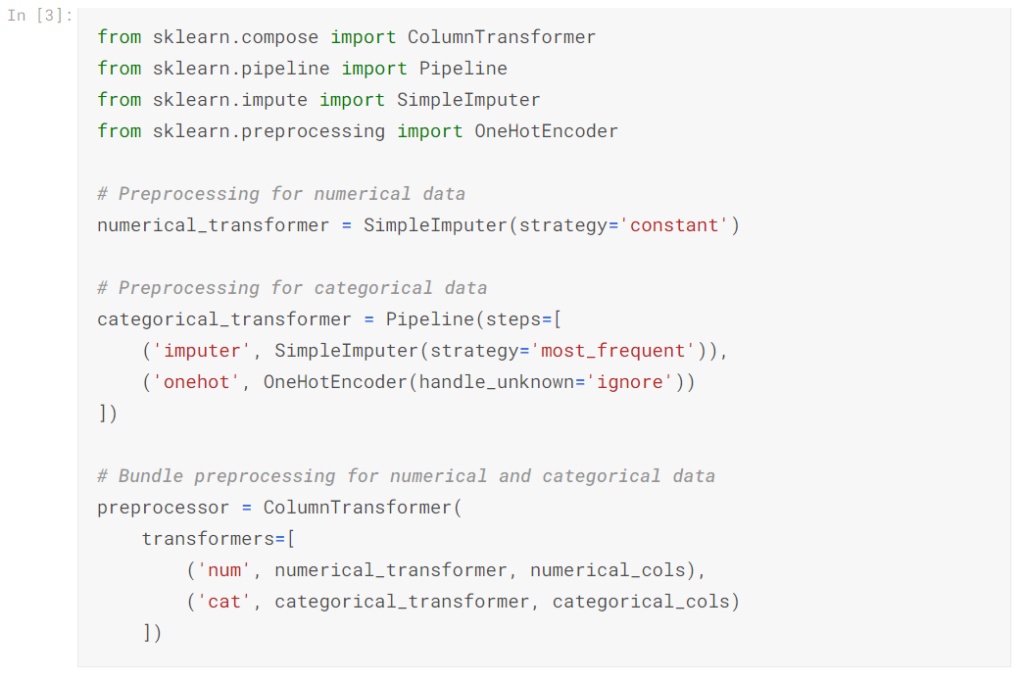
ステップ1:前処理ステップを定義する
パイプラインが前処理ステップとモデリングステップをバンドルする方法と同様に、ColumnTransformerクラスを使用してさまざまな前処理ステップをバンドルします。以下のコード:
- 数値データの欠測値を代入する
- ワンホットエンコーディングをカテゴリデータに適用する
ステップ2:モデルを定義する
次に、おなじみのRandomForestRegressorクラスを使用してランダムフォレストモデルを定義します。

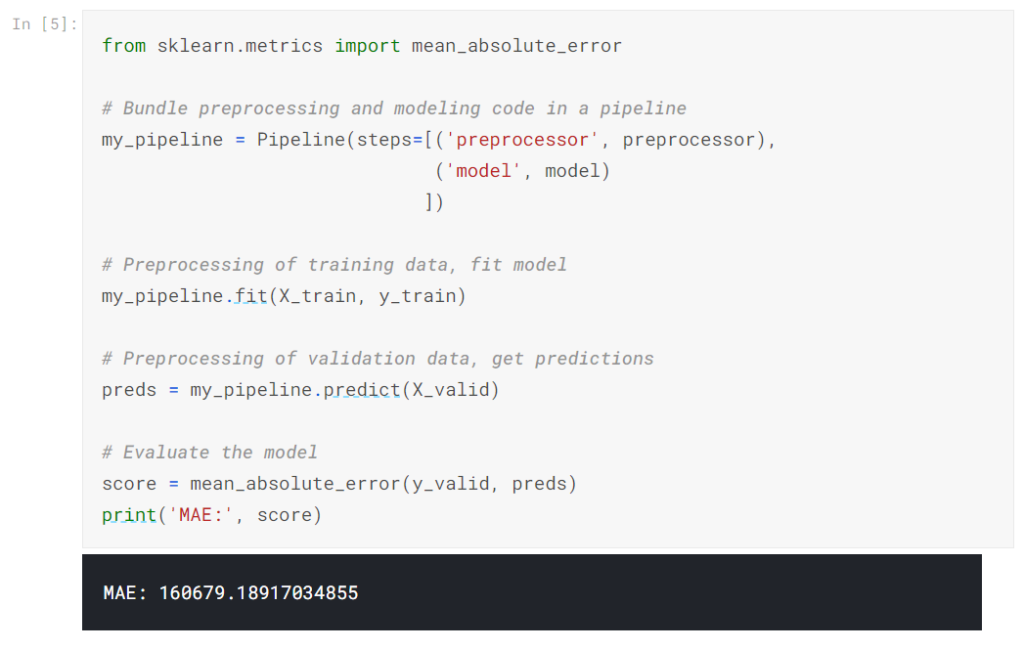
ステップ3:パイプラインを作成して評価する
最後に、Pipelineクラスを使用して、前処理とモデリングのステップをバンドルするパイプラインを定義します。注意すべき重要なことがいくつかあります。
- パイプラインを使用して、トレーニングデータを前処理し、モデルを1行のコードに適合させます。 (対照的に、パイプラインがないと、代入、ワンホットエンコーディング、モデルトレーニングを別々のステップで実行する必要があります。これは、数値変数とカテゴリ変数の両方を処理する必要がある場合に特に厄介になります!)
- パイプラインでは、X_validの未処理の特徴をpredict()コマンドに提供し、パイプラインは予測を生成する前に特徴を自動的に前処理します。 (ただし、パイプラインがない場合、予測を行う前に検証データを前処理することを忘れないでください。)
結論
パイプラインは、機械学習コードをクリーンアップしてエラーを回避するのに役立ち、高度なデータ前処理を伴うワークフローに特に役立ちます。
あなたの番
次の演習でパイプラインを使用して、事前に使用します
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
