このチュートリアルでは、勾配ブースティングを使用してモデルを構築および最適化する方法を学習します。この方法は、多くのKaggleの競争を支配し、さまざまなデータセットで最先端の結果を達成します。
はじめに
前書き このコースの多くでは、ランダムフォレスト法を使用して予測を行いました。これは、多くの決定木の予測を平均するだけで、単一の決定木よりも優れたパフォーマンスを実現します。
ランダムフォレスト法を「アンサンブル法」と呼びます。定義上、アンサンブル手法は、いくつかのモデルの予測を組み合わせます(たとえば、ランダムフォレストの場合はいくつかの木)。
次に、勾配ブースティングと呼ばれる別のアンサンブル手法について学習します。
勾配ブースティング
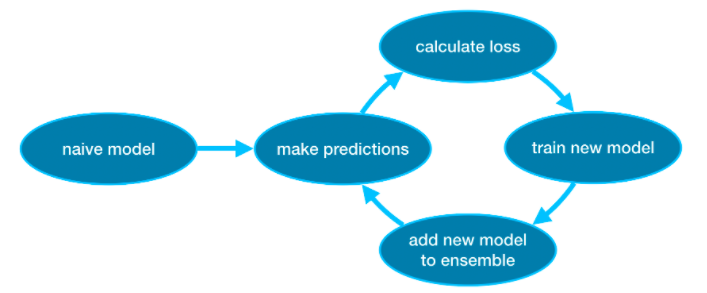
勾配ブースティングは、サイクルを経てモデルをアンサンブルに繰り返し追加する方法です。
それは、単一のモデルでアンサンブルを初期化することから始まります。その予測はかなり単純なものになる可能性があります。 (予測が非常に不正確であっても、その後のアンサンブルへの追加により、これらのエラーに対処できます。)
次に、サイクルを開始します。
- まず、現在のアンサンブルを使用して、データセット内の各観測値の予測を生成します。予測を行うために、アンサンブル内のすべてのモデルからの予測を追加します。
- これらの予測は、損失関数(たとえば、平均二乗誤差など)を計算するために使用されます。
- 次に、損失関数を使用して、アンサンブルに追加される新しいモデルを適合させます。具体的には、この新しいモデルをアンサンブルに追加することで損失が減少するように、モデルパラメーターを決定します。 (補足:「勾配ブースティング」の「勾配」は、損失関数で勾配降下法を使用して、この新しいモデルのパラメーターを決定するという事実を指します。)
- 最後に、新しいモデルをアンサンブルに追加し、…
- …繰り返します!
例えば
X_train、X_valid、y_train、およびy_validにトレーニングおよび検証データをロードすることから始めます。
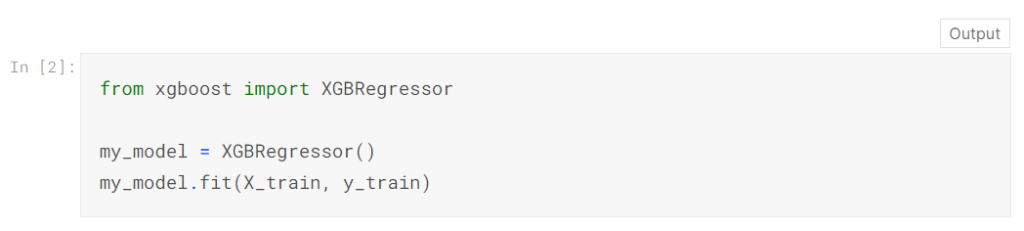
この例では、XGBoostライブラリを使用します。 XGBoostは、極端な勾配ブースティングの略で、パフォーマンスと速度に焦点を当てたいくつかの追加機能を備えた勾配ブースティングの実装です。 (Scikit-learnには別のバージョンの勾配ブースティングがありますが、XGBoostにはいくつかの技術的な利点があります。)
次のコードセルでは、XGBoost用のscikit-learn API(xgboost.XGBRegressor)をインポートします。これにより、scikit-learnの場合と同じように、モデルを構築して適合させることができます。出力に示されているように、XGBRegressorクラスには多くの調整可能なパラメーターがあります。これらについてはすぐに学習します。
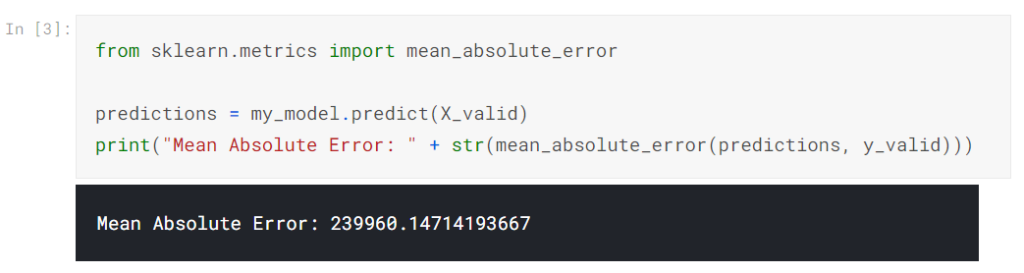
また、予測を行い、モデルを評価します。
パラメータチューニング
XGBoostには、精度とトレーニング速度に劇的な影響を与える可能性のあるいくつかのパラメーターがあります。理解しておくべき最初のパラメーターは次のとおりです。
n_estimators
n_estimatorsは、上記のモデリングサイクルを通過する回数を指定します。これは、アンサンブルに含めるモデルの数と同じです。
- 値が低すぎると、適合が不十分になり、トレーニングデータとテストデータの両方の予測が不正確になります。
- 値が高すぎると過剰適合が発生し、トレーニングデータの予測は正確になりますが、テストデータの予測は不正確になります(これが私たちの関心事です)。
一般的な値の範囲は100〜1000ですが、これは以下で説明するlearning_rateパラメーターに大きく依存します。
アンサンブル内のモデルの数を設定するコードは次のとおりです。

Early_stopping_rounds
Early_stopping_roundsは、n_estimatorsの理想的な値を自動的に見つける方法を提供します。早期停止により、n_estimatorsのハードストップが行われていなくても、検証スコアの改善が停止するとモデルの反復が停止します。 n_estimatorsに高い値を設定してから、early_stopping_roundsを使用して、反復を停止する最適な時間を見つけるのが賢明です。
ランダムな偶然により、検証スコアが改善されない単一のラウンドが発生することがあるため、停止する前に許容するストレート劣化のラウンド数の数を指定する必要があります。 Early_stopping_rounds = 5を設定するのが妥当な選択です。この場合、検証スコアが5回連続して低下した後に停止します。
Early_stopping_roundsを使用する場合は、検証スコアを計算するためのデータも確保する必要があります。これは、eval_setパラメーターを設定することによって行われます。
上記の例を変更して、早期停止を含めることができます。

後でモデルをすべてのデータに適合させたい場合は、早期停止で実行したときに最適であるとわかった値にn_estimatorsを設定します。
Learning_rate
各コンポーネントモデルからの予測を単純に合計するだけで予測を取得する代わりに、各モデルからの予測に少数(学習率と呼ばれる)を掛けてから追加することができます。
これは、アンサンブルに追加する各ツリーが役に立たないことを意味します。したがって、過剰適合することなく、n_estimatorsに高い値を設定できます。早期打ち切りを使用すると、適切なツリー数が自動的に決定されます。
一般に、学習率が低く、推定量が多いと、より正確なXGBoostモデルが生成されますが、サイクル全体でより多くの反復が行われるため、モデルのトレーニングに時間がかかります。デフォルトでは、XGBoostはlearning_rate = 0.1を設定します。
上記の例を変更して学習率を変更すると、次のコードが生成されます。

n_jobs
実行時間が考慮される大規模なデータセットでは、並列処理を使用してモデルをより高速に構築できます。パラメータn_jobsをマシンのコア数と同じに設定するのが一般的です。小さいデータセットでは、これは役に立ちません。
結果として得られるモデルはこれ以上良くなることはないので、フィッティング時間のマイクロ最適化は通常、気を散らすだけです。ただし、fitコマンドの実行中に長時間待機する大規模なデータセットでは便利です。
変更された例は次のとおりです。

結論
XGBoostは、標準の表形式データ(画像やビデオなどのよりエキゾチックなタイプのデータではなく、Pandas DataFramesに保存するタイプのデータ)を操作するための主要なソフトウェアライブラリです。注意深いパラメータ調整により、非常に正確なモデルをトレーニングできます。
あなたの番
次の演習では、XGBoostを使用して独自のモデルをトレーニングしてください。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
