はじめに
デシジョンツリーはあなたに難しい決定を残します。 リーフがたくさんある深いツリーは、各予測がリーフの数軒の家からの履歴データから得られているため、過学習します。 ただし、リーフの少ない浅いツリーは、生データで多くの区別を取得できないため、パフォーマンスが低下します。
今日の最も洗練されたモデリング技術でさえ、学習不足と過学習の間のこの緊張に直面しています。 しかし、多くのモデルには、パフォーマンスの向上につながる可能性のある巧妙なアイデアがあります。 例としてランダムフォレストを見てみましょう。
ランダムフォレストは多くのツリーを使用し、各コンポーネントツリーの予測を平均して予測を行います。 通常、単一のデシジョンツリーよりもはるかに優れた予測精度があり、デフォルトのパラメーターでうまく機能します。 モデリングを続けると、さらに優れたパフォーマンスでより多くのモデルを学習できますが、それらの多くは適切なパラメーターの取得に敏感です。
例えば
データを数回ロードするコードを見てきました。 データの読み込みの最後に、次の変数があります。
train_X
val_X
train_y
val_y
scikit-learnでデシジョンツリーを構築したのと同様に、ランダムフォレストモデルを構築します。今回は、DecisionTreeRegressorの代わりにRandomForestRegressorクラスを使用します。
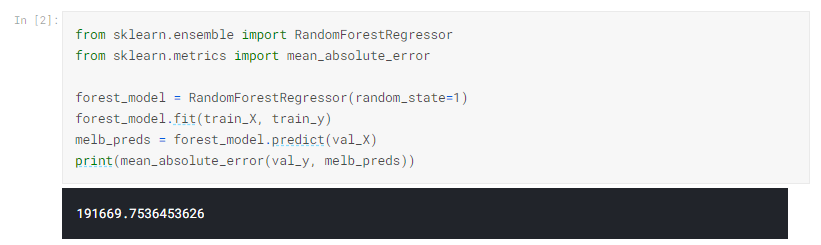
結論
さらなる改善の余地がある可能性がありますが、これは、250,000の最良のデシジョンツリーエラーを超える大きな改善です。 単一のデシジョンツリーの最大深度を変更したのと同じように、ランダムフォレストのパフォーマンスを変更できるパラメーターがあります。 しかし、ランダムフォレストモデルの最も優れた機能の1つは、この調整を行わなくても、一般的に適切に機能することです。
あなたの番です
ランダムフォレストモデルを自分で使用してみて、モデルがどの程度改善されるかを確認してください。
 | データサイエンスの森 Kaggleの歩き方 [ 坂本俊之 ] 価格:2,904円 |
 | 価格:3,608円 |
 | すぐに使える!業務で実践できる!PythonによるAI・機械学習・深層学習アプリ [ クジラ飛行机 ] 価格:3,520円 |
